7.1. 二叉树¶
「二叉树 Binary Tree」是一种非线性数据结构,代表着祖先与后代之间的派生关系,体现着“一分为二”的分治逻辑。类似于链表,二叉树也是以结点为单位存储的,结点包含「值」和两个「指针」。
/* 链表结点类 */
class TreeNode {
val: number;
left: TreeNode | null;
right: TreeNode | null;
constructor(val?: number, left?: TreeNode | null, right?: TreeNode | null) {
this.val = val === undefined ? 0 : val; // 结点值
this.left = left === undefined ? null : left; // 左子结点指针
this.right = right === undefined ? null : right; // 右子结点指针
}
}
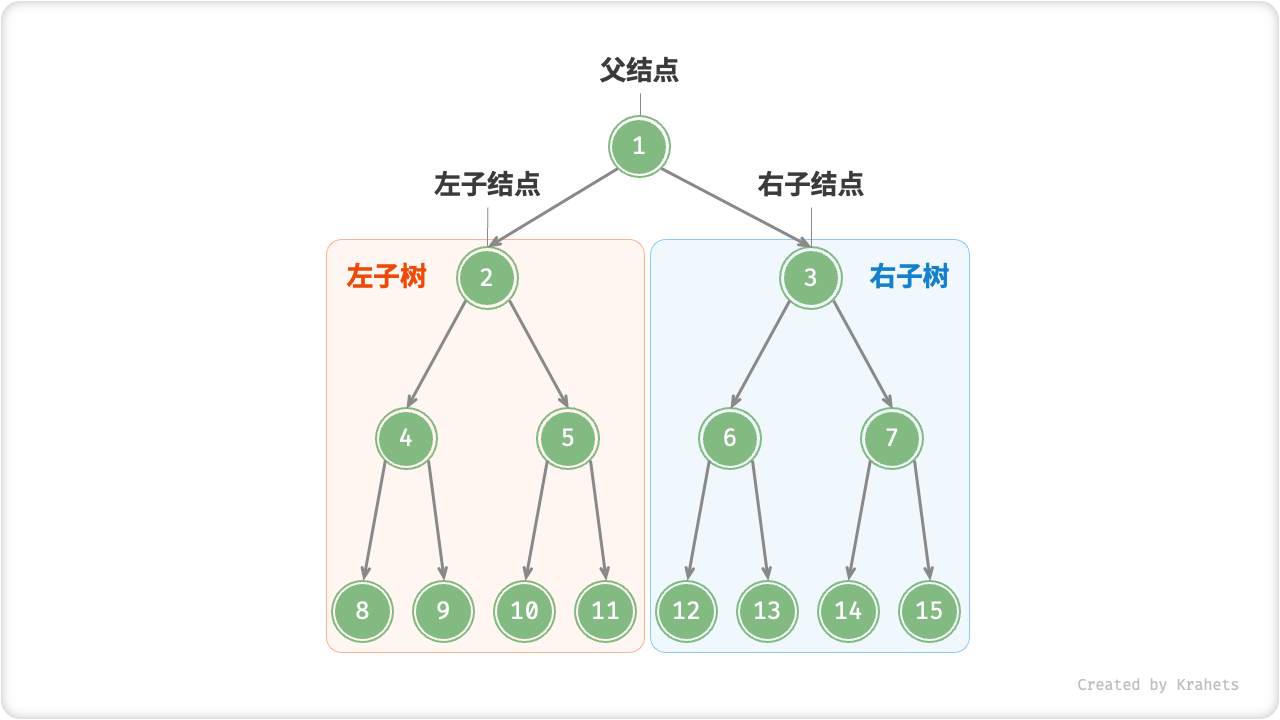
结点的两个指针分别指向「左子结点 Left Child Node」和「右子结点 Right Child Node」,并且称该结点为两个子结点的「父结点 Parent Node」。给定二叉树某结点,将左子结点以下的树称为该结点的「左子树 Left Subtree」,右子树同理。
除了叶结点外,每个结点都有子结点和子树。例如,若将下图的「结点 2」看作父结点,那么其左子结点和右子结点分别为「结点 4」和「结点 5」,左子树和右子树分别为「结点 4 及其以下结点形成的树」和「结点 5 及其以下结点形成的树」。
7.1.1. 二叉树常见术语¶
二叉树的术语较多,建议尽量理解并记住。后续可能遗忘,可以在需要使用时回来查看确认。
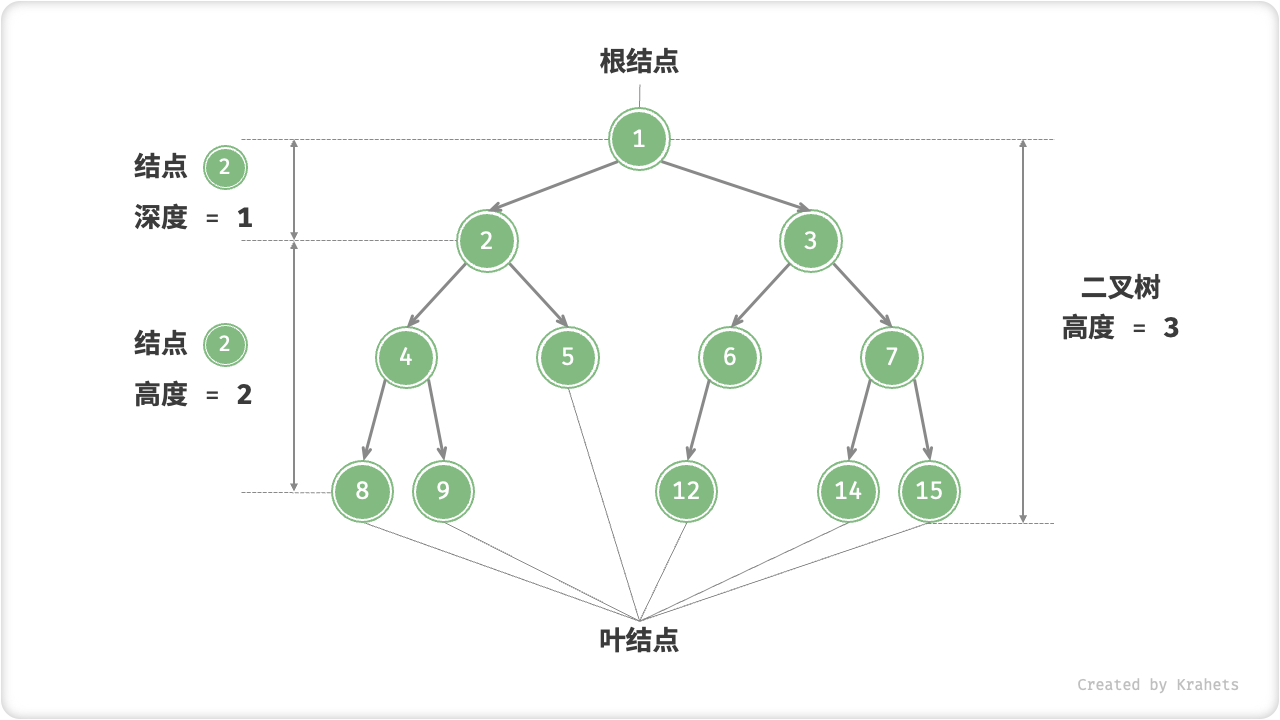
- 「根结点 Root Node」:二叉树最顶层的结点,其没有父结点;
- 「叶结点 Leaf Node」:没有子结点的结点,其两个指针都指向 \(\text{null}\) ;
- 结点所处「层 Level」:从顶至底依次增加,根结点所处层为 1 ;
- 结点「度 Degree」:结点的子结点数量。二叉树中,度的范围是 0, 1, 2 ;
- 「边 Edge」:连接两个结点的边,即结点指针;
- 二叉树「高度」:二叉树中根结点到最远叶结点走过边的数量;
- 结点「深度 Depth」 :根结点到该结点走过边的数量;
- 结点「高度 Height」:最远叶结点到该结点走过边的数量;
高度与深度的定义
值得注意,我们通常将「高度」和「深度」定义为“走过边的数量”,而有些题目或教材会将其定义为“走过结点的数量”,此时高度或深度都需要 + 1 。
7.1.2. 二叉树基本操作¶
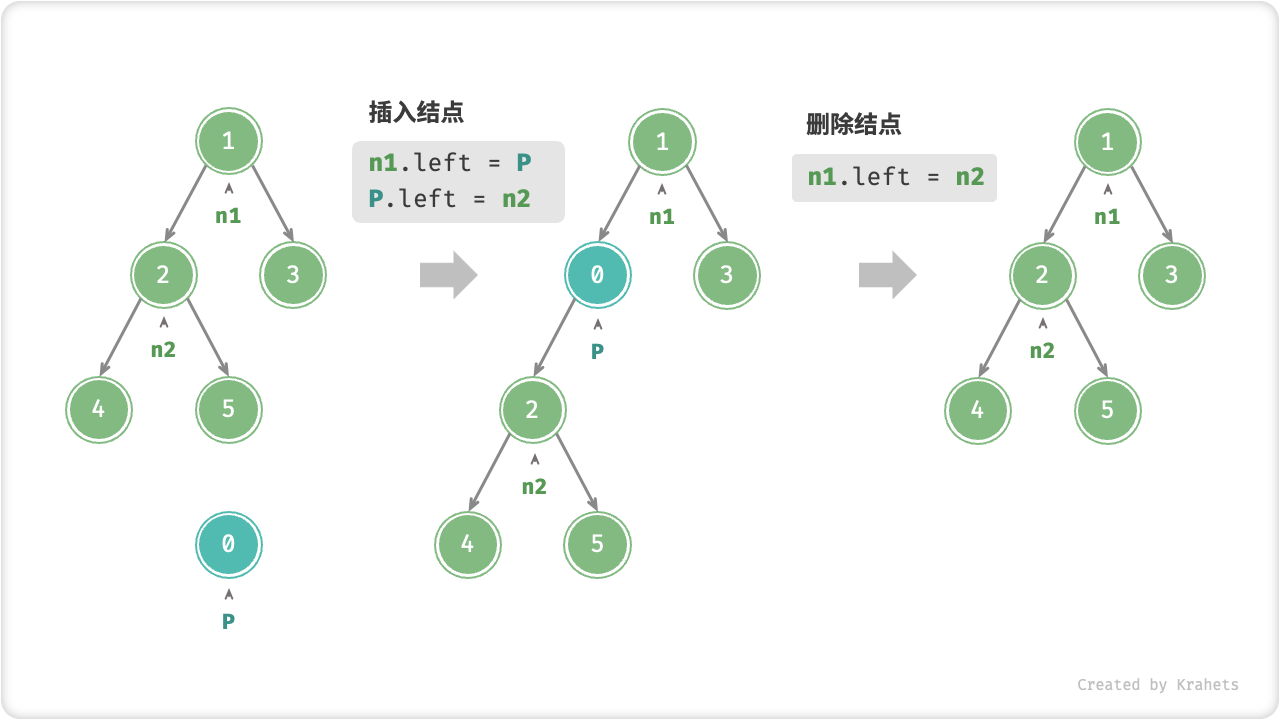
初始化二叉树。与链表类似,先初始化结点,再构建引用指向(即指针)。
插入与删除结点。与链表类似,插入与删除结点都可以通过修改指针实现。
Note
插入结点会改变二叉树的原有逻辑结构,删除结点往往意味着删除了该结点的所有子树。因此,二叉树中的插入与删除一般都是由一套操作配合完成的,这样才能实现有意义的操作。
7.1.3. 常见二叉树类型¶
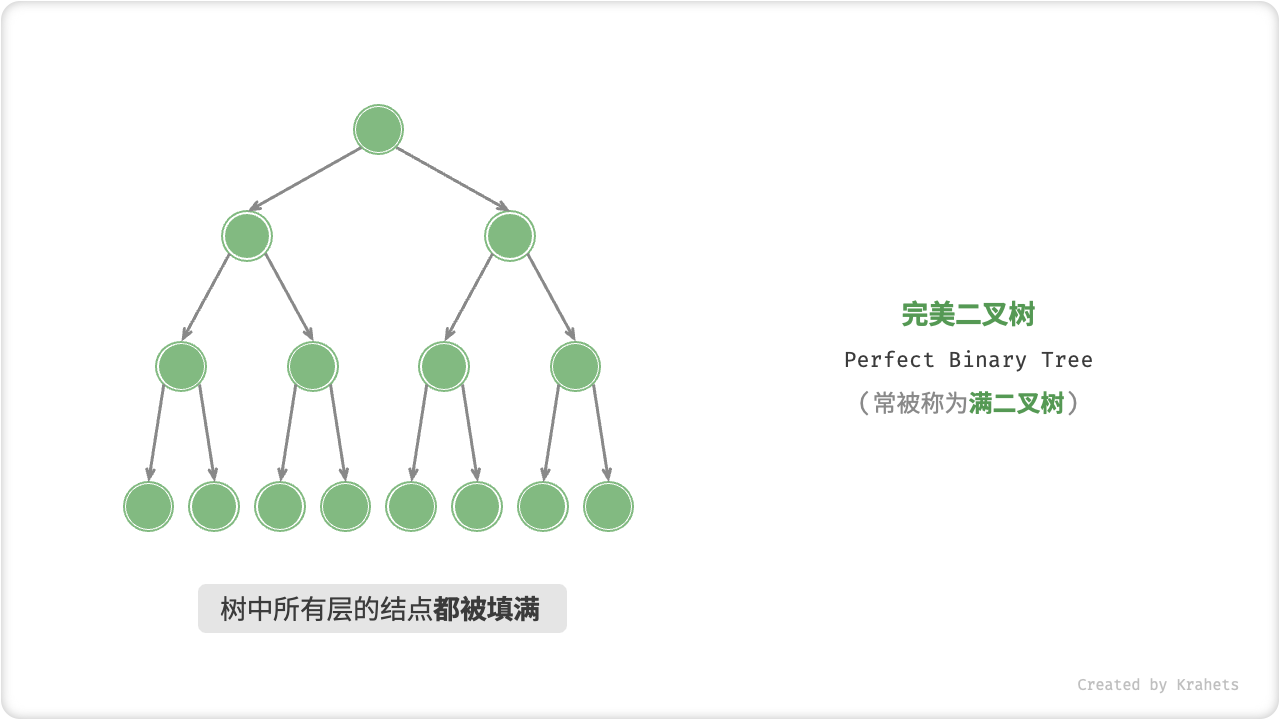
完美二叉树¶
「完美二叉树 Perfect Binary Tree」的所有层的结点都被完全填满。在完美二叉树中,所有结点的度 = 2 ;若树高度 \(= h\) ,则结点总数 \(= 2^{h+1} - 1\) ,呈标准的指数级关系,反映着自然界中常见的细胞分裂。
Tip
在中文社区中,完美二叉树常被称为「满二叉树」,请注意与完满二叉树区分。
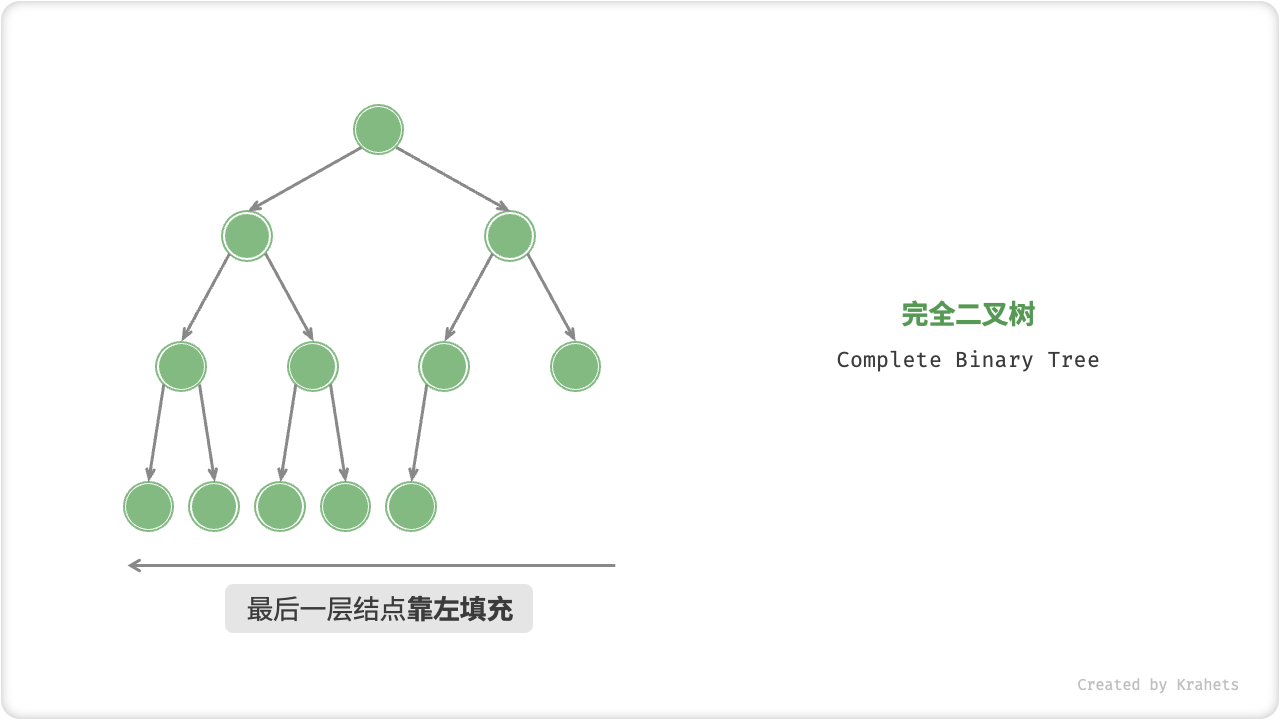
完全二叉树¶
「完全二叉树 Complete Binary Tree」只有最底层的结点未被填满,且最底层结点尽量靠左填充。
完全二叉树非常适合用数组来表示。如果按照层序遍历序列的顺序来存储,那么空结点 null 一定全部出现在序列的尾部,因此我们就可以不用存储这些 null 了。
完满二叉树¶
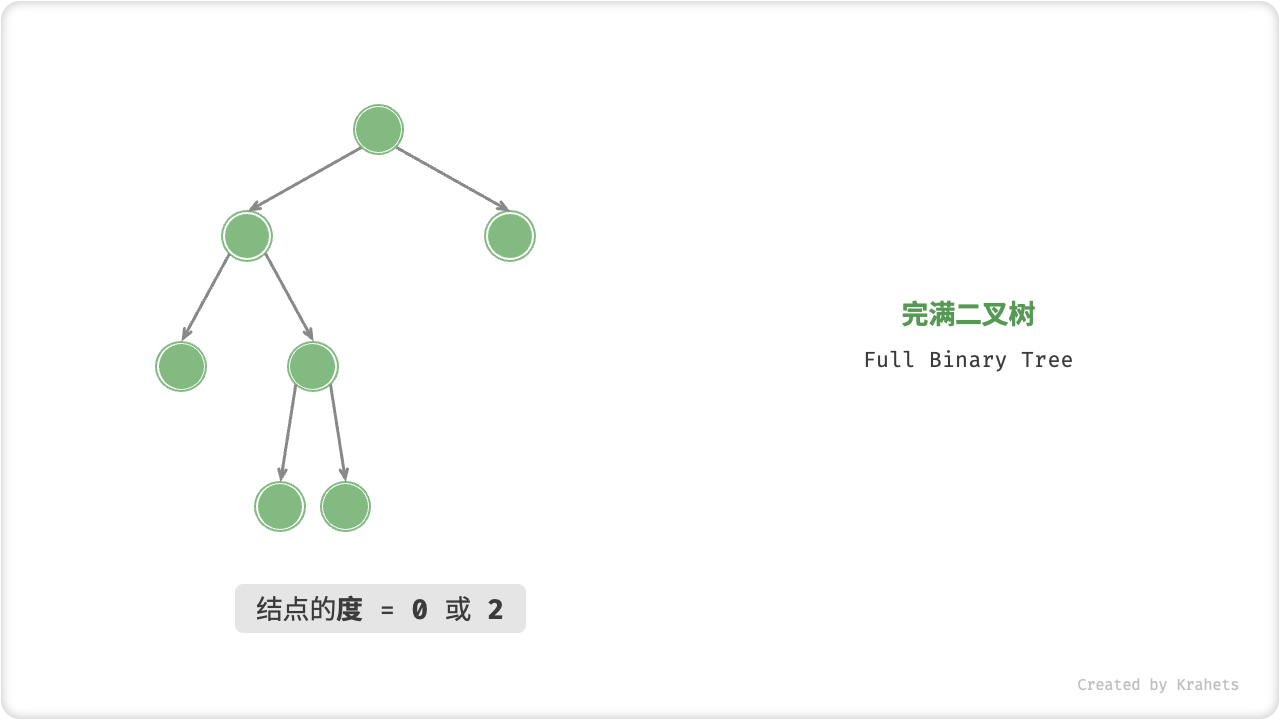
「完满二叉树 Full Binary Tree」除了叶结点之外,其余所有结点都有两个子结点。
平衡二叉树¶
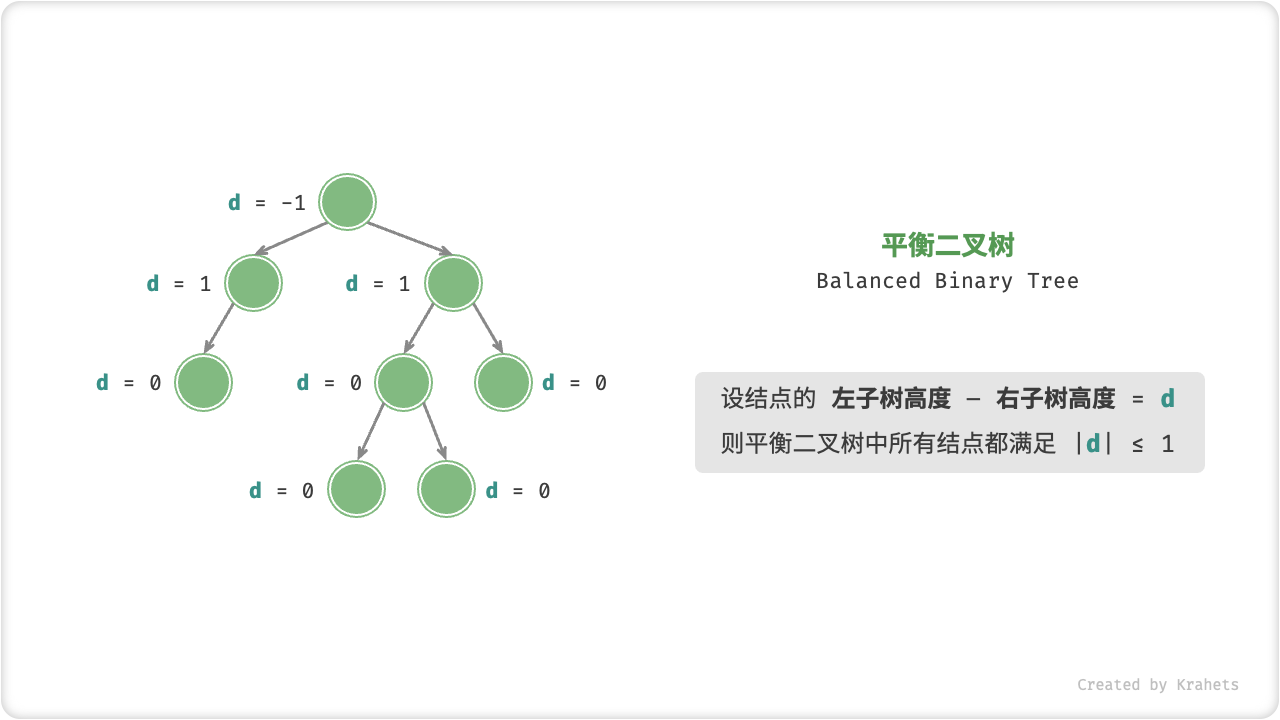
「平衡二叉树 Balanced Binary Tree」中任意结点的左子树和右子树的高度之差的绝对值 \(\leq 1\) 。
7.1.4. 二叉树的退化¶
当二叉树的每层的结点都被填满时,达到「完美二叉树」;而当所有结点都偏向一边时,二叉树退化为「链表」。
- 完美二叉树是一个二叉树的“最佳状态”,可以完全发挥出二叉树“分治”的优势;
- 链表则是另一个极端,各项操作都变为线性操作,时间复杂度退化至 \(O(n)\) ;

如下表所示,在最佳和最差结构下,二叉树的叶结点数量、结点总数、高度等达到极大或极小值。
| 完美二叉树 | 链表 | |
|---|---|---|
| 第 \(i\) 层的结点数量 | \(2^{i-1}\) | \(1\) |
| 树的高度为 \(h\) 时的叶结点数量 | \(2^h\) | \(1\) |
| 树的高度为 \(h\) 时的结点总数 | \(2^{h+1} - 1\) | \(h + 1\) |
| 树的结点总数为 \(n\) 时的高度 | \(\log_2 (n+1) - 1\) | \(n - 1\) |
7.1.5. 二叉树表示方式 *¶
我们一般使用二叉树的「链表表示」,即存储单位为结点 TreeNode ,结点之间通过指针(引用)相连接。本文前述示例代码展示了二叉树在链表表示下的各项基本操作。
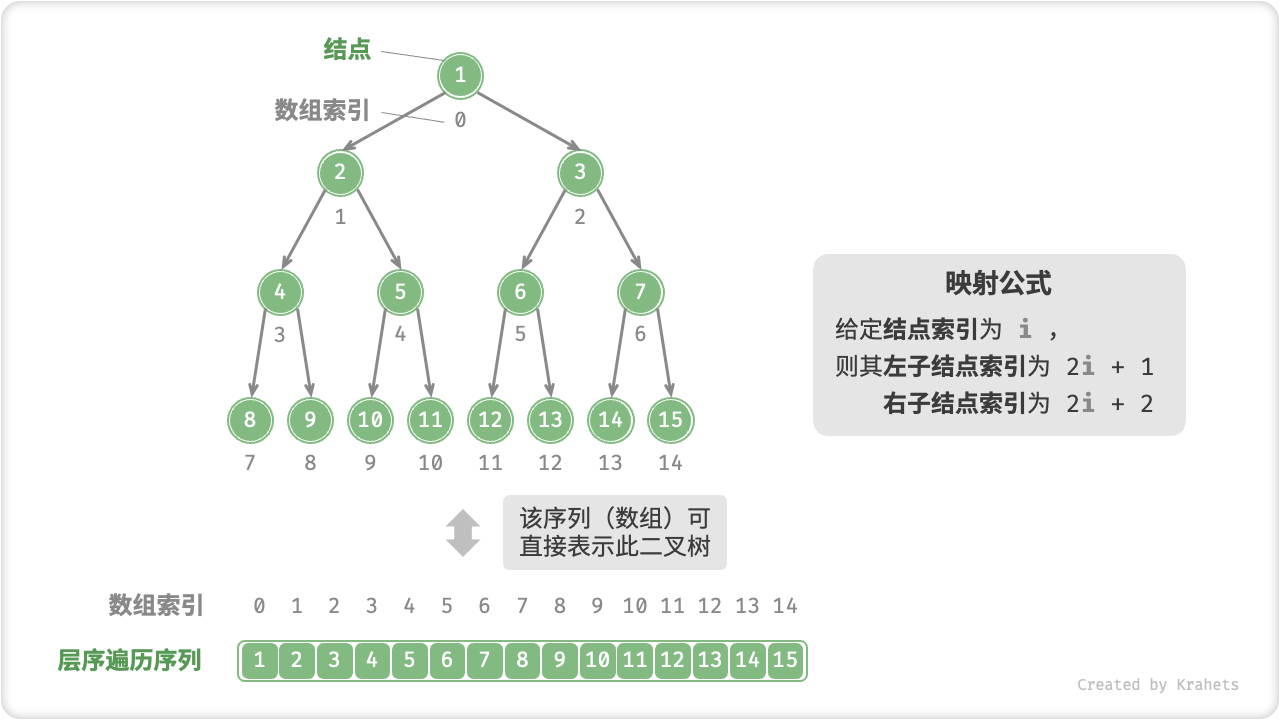
那能否可以用「数组表示」二叉树呢?答案是肯定的。先来分析一个简单案例,给定一个「完美二叉树」,将结点按照层序遍历的顺序编号(从 0 开始),那么可以推导得出父结点索引与子结点索引之间的「映射公式」:设结点的索引为 \(i\) ,则该结点的左子结点索引为 \(2i + 1\) 、右子结点索引为 \(2i + 2\) 。
本质上,映射公式的作用就是链表中的指针。对于层序遍历序列中的任意结点,我们都可以使用映射公式来访问子结点。因此,可以直接使用层序遍历序列(即数组)来表示完美二叉树。
然而,完美二叉树只是个例,二叉树中间层往往存在许多空结点(即 null ),而层序遍历序列并不包含这些空结点,并且我们无法单凭序列来猜测空结点的数量和分布位置,即理论上存在许多种二叉树都符合该层序遍历序列。显然,这种情况无法使用数组来存储二叉树。
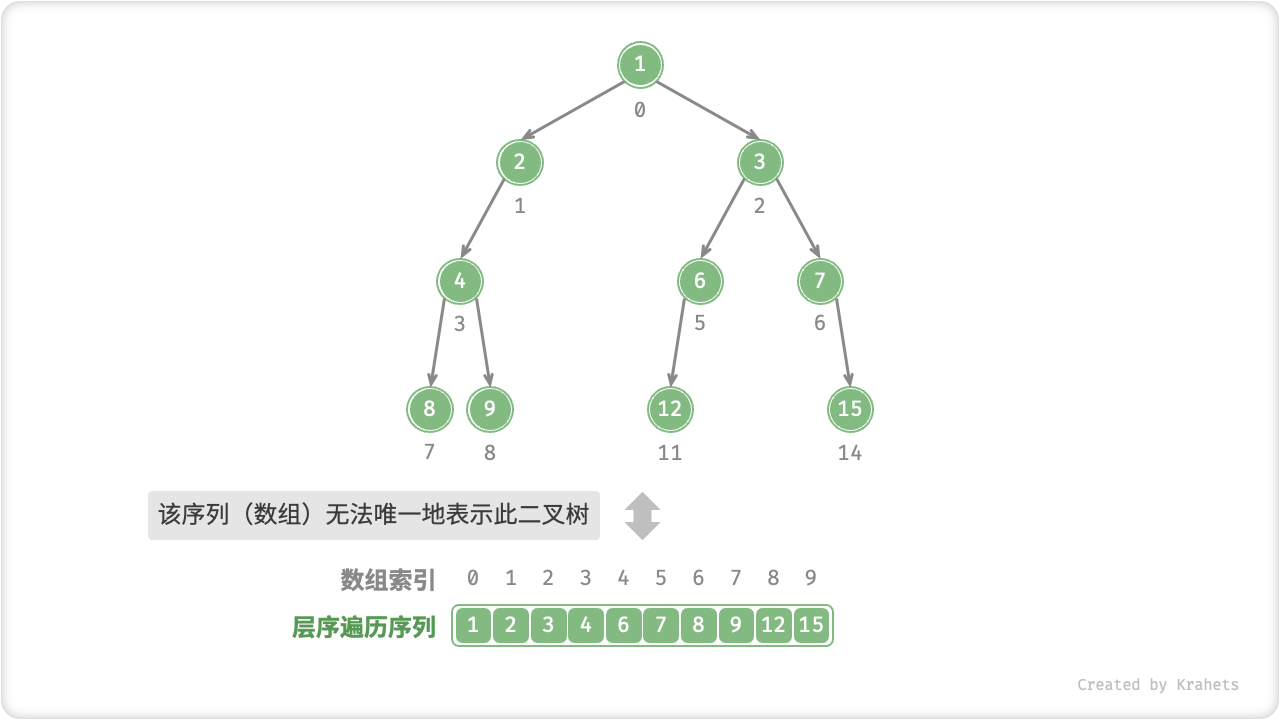
为了解决此问题,考虑按照完美二叉树的形式来表示所有二叉树,即在序列中使用特殊符号来显式地表示“空位”。如下图所示,这样处理后,序列(数组)就可以唯一表示二叉树了。
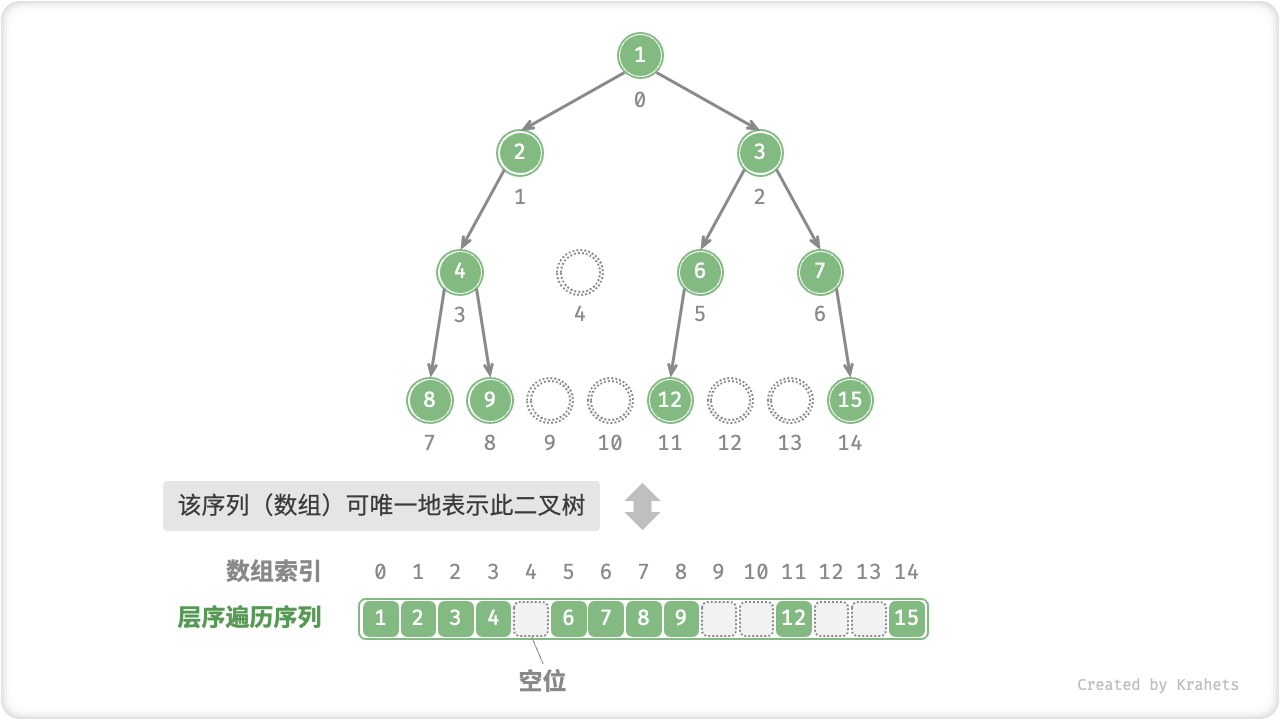
回顾「完全二叉树」的定义,其只有最底层有空结点,并且最底层的结点尽量靠左,因而所有空结点都一定出现在层序遍历序列的末尾。因为我们先验地确定了空位的位置,所以在使用数组表示完全二叉树时,可以省略存储“空位”。因此,完全二叉树非常适合使用数组来表示。
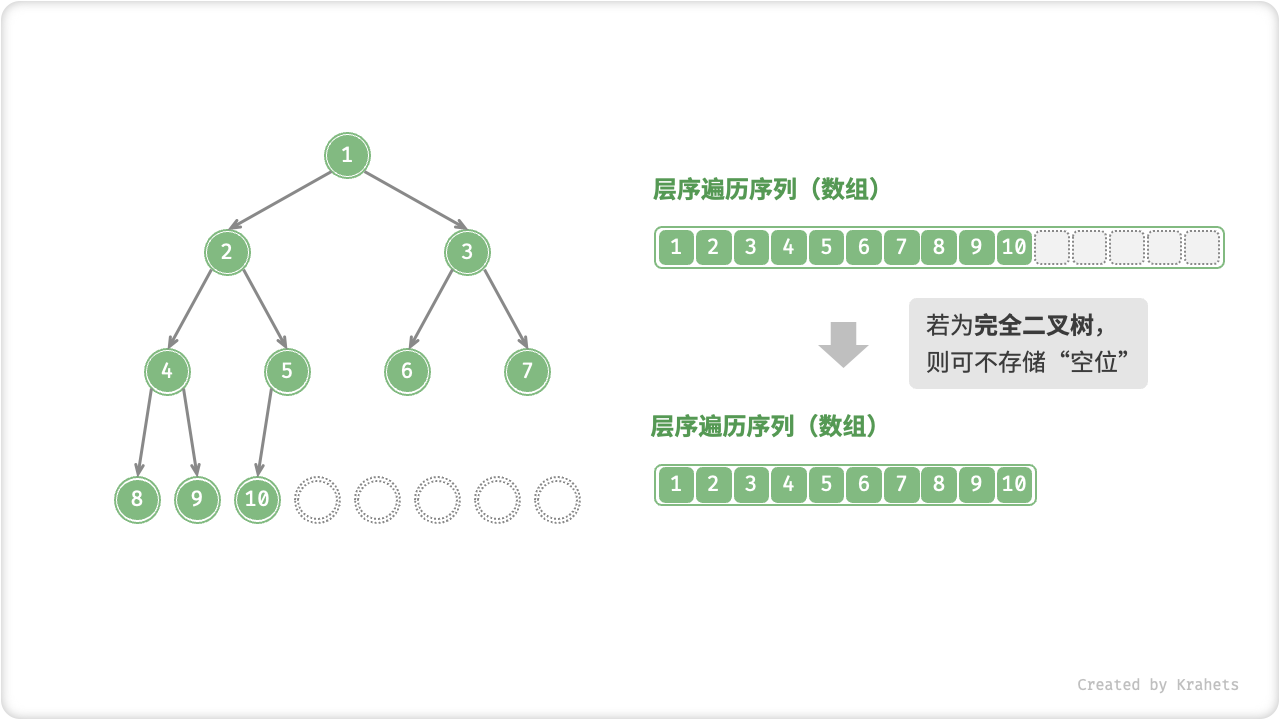
数组表示有两个优点: 一是不需要存储指针,节省空间;二是可以随机访问结点。然而,当二叉树中的“空位”很多时,数组中只包含很少结点的数据,空间利用率很低。