23 KiB
| comments |
|---|
| true |
堆
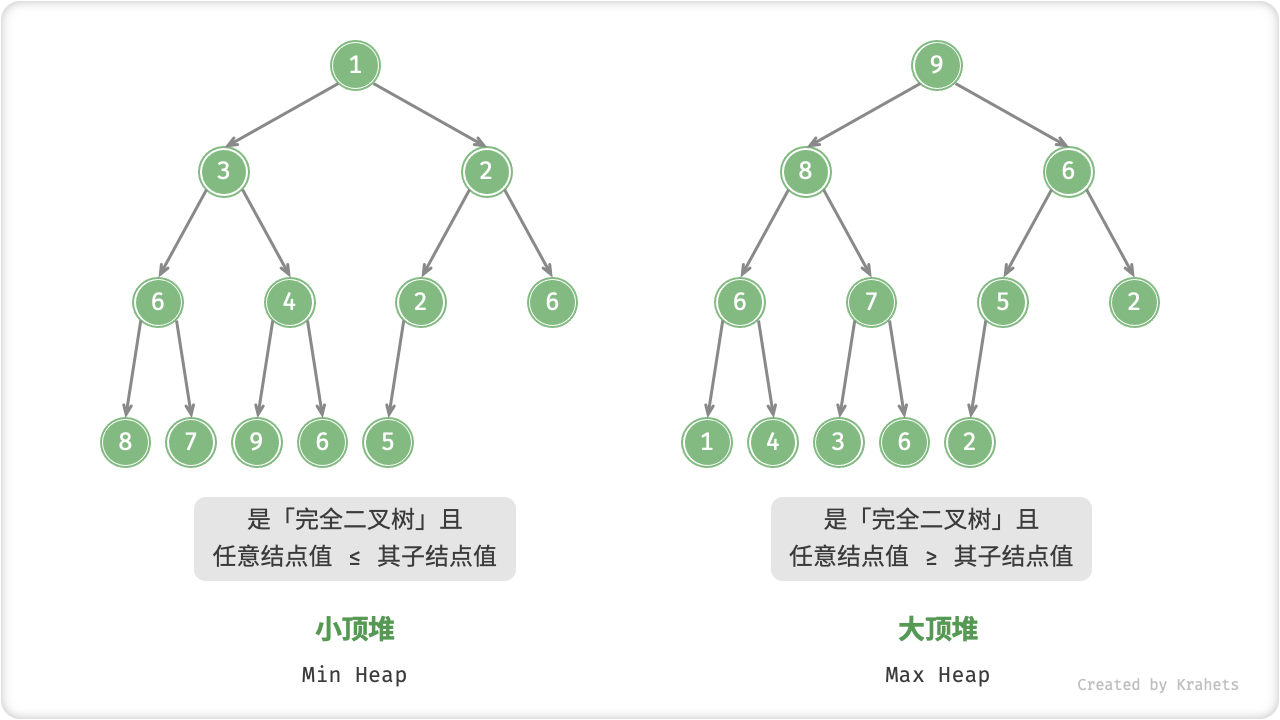
「堆 Heap」是一颗限定条件下的「完全二叉树」。根据成立条件,堆主要分为两种类型:
- 「大顶堆 Max Heap」,任意结点的值
\geq其子结点的值; - 「小顶堆 Min Heap」,任意结点的值
\leq其子结点的值;
堆术语与性质
- 由于堆是完全二叉树,因此最底层结点靠左填充,其它层结点皆被填满。
- 二叉树中的根结点对应「堆顶」,底层最靠右结点对应「堆底」。
- 对于大顶堆 / 小顶堆,其堆顶元素(即根结点)的值最大 / 最小。
堆常用操作
值得说明的是,多数编程语言提供的是「优先队列 Priority Queue」,其是一种抽象数据结构,定义为具有出队优先级的队列。
而恰好,堆的定义与优先队列的操作逻辑完全吻合,大顶堆就是一个元素从大到小出队的优先队列。从使用角度看,我们可以将「优先队列」和「堆」理解为等价的数据结构。因此,本文与代码对两者不做特别区分,统一使用「堆」来命名。
堆的常用操作见下表(方法命名以 Java 为例)。
Table. 堆的常用操作
| 方法 | 描述 | 时间复杂度 |
|---|---|---|
| add() | 元素入堆 | O(\log n) |
| poll() | 堆顶元素出堆 | O(\log n) |
| peek() | 访问堆顶元素(大 / 小顶堆分别为最大 / 小值) | O(1) |
| size() | 获取堆的元素数量 | O(1) |
| isEmpty() | 判断堆是否为空 | O(1) |
我们可以直接使用编程语言提供的堆类(或优先队列类)。
!!! tip
类似于排序中“从小到大排列”和“从大到小排列”,“大顶堆”和“小顶堆”可仅通过修改 Comparator 来互相转换。
=== "Java"
```java title="heap.java"
/* 初始化堆 */
// 初始化小顶堆
Queue<Integer> minHeap = new PriorityQueue<>();
// 初始化大顶堆(使用 lambda 表达式修改 Comparator 即可)
Queue<Integer> maxHeap = new PriorityQueue<>((a, b) -> { return b - a; });
/* 元素入堆 */
maxHeap.add(1);
maxHeap.add(3);
maxHeap.add(2);
maxHeap.add(5);
maxHeap.add(4);
/* 获取堆顶元素 */
int peek = maxHeap.peek(); // 5
/* 堆顶元素出堆 */
// 出堆元素会形成一个从大到小的序列
peek = heap.poll(); // 5
peek = heap.poll(); // 4
peek = heap.poll(); // 3
peek = heap.poll(); // 2
peek = heap.poll(); // 1
/* 获取堆大小 */
int size = maxHeap.size();
/* 判断堆是否为空 */
boolean isEmpty = maxHeap.isEmpty();
/* 输入列表并建堆 */
minHeap = new PriorityQueue<>(Arrays.asList(1, 3, 2, 5, 4));
```
=== "C++"
```cpp title="heap.cpp"
```
=== "Python"
```python title="heap.py"
```
=== "Go"
```go title="heap.go"
// Go 语言中可以通过实现 heap.Interface 来构建整数大顶堆
// 实现 heap.Interface 需要同时实现 sort.Interface
type intHeap []any
// Push heap.Interface 的方法,实现推入元素到堆
func (h *intHeap) Push(x any) {
// Push 和 Pop 使用 pointer receiver 作为参数
// 因为它们不仅会对切片的内容进行调整,还会修改切片的长度。
*h = append(*h, x.(int))
}
// Pop heap.Interface 的方法,实现弹出堆顶元素
func (h *intHeap) Pop() any {
// 待出堆元素存放在最后
last := (*h)[len(*h)-1]
*h = (*h)[:len(*h)-1]
return last
}
// Len sort.Interface 的方法
func (h *intHeap) Len() int {
return len(*h)
}
// Less sort.Interface 的方法
func (h *intHeap) Less(i, j int) bool {
// 如果实现小顶堆,则需要调整为小于号
return (*h)[i].(int) > (*h)[j].(int)
}
// Swap sort.Interface 的方法
func (h *intHeap) Swap(i, j int) {
(*h)[i], (*h)[j] = (*h)[j], (*h)[i]
}
// Top 获取堆顶元素
func (h *intHeap) Top() any {
return (*h)[0]
}
/* Driver Code */
func TestHeap(t *testing.T) {
/* 初始化堆 */
// 初始化大顶堆
maxHeap := &intHeap{}
heap.Init(maxHeap)
/* 元素入堆 */
// 调用 heap.Interface 的方法,来添加元素
heap.Push(maxHeap, 1)
heap.Push(maxHeap, 3)
heap.Push(maxHeap, 2)
heap.Push(maxHeap, 4)
heap.Push(maxHeap, 5)
/* 获取堆顶元素 */
top := maxHeap.Top()
fmt.Printf("堆顶元素为 %d\n", top)
/* 堆顶元素出堆 */
// 调用 heap.Interface 的方法,来移除元素
heap.Pop(maxHeap)
heap.Pop(maxHeap)
heap.Pop(maxHeap)
heap.Pop(maxHeap)
heap.Pop(maxHeap)
/* 获取堆大小 */
size := len(*maxHeap)
fmt.Printf("堆元素数量为 %d\n", size)
/* 判断堆是否为空 */
isEmpty := len(*maxHeap) == 0
fmt.Printf("堆是否为空 %t\n", isEmpty)
}
```
=== "JavaScript"
```js title="heap.js"
```
=== "TypeScript"
```typescript title="heap.ts"
```
=== "C"
```c title="heap.c"
```
=== "C#"
```csharp title="heap.cs"
```
=== "Swift"
```swift title="heap.swift"
// Swift 未提供内置 heap 类
```
堆的实现
下文实现的是「大顶堆」,若想转换为「小顶堆」,将所有大小逻辑判断取逆(例如将 \geq 替换为 \leq )即可,有兴趣的同学可自行实现。
堆的存储与表示
在二叉树章节我们学过,「完全二叉树」非常适合使用「数组」来表示,而堆恰好是一颗完全二叉树,因而我们采用「数组」来存储「堆」。
二叉树指针。使用数组表示二叉树时,元素代表结点值,索引代表结点在二叉树中的位置,而结点指针通过索引映射公式来实现。
具体地,给定索引 i ,那么其左子结点索引为 2i + 1 、右子结点索引为 2i + 2 、父结点索引为 (i - 1) / 2 (向下整除)。当索引越界时,代表空结点或结点不存在。
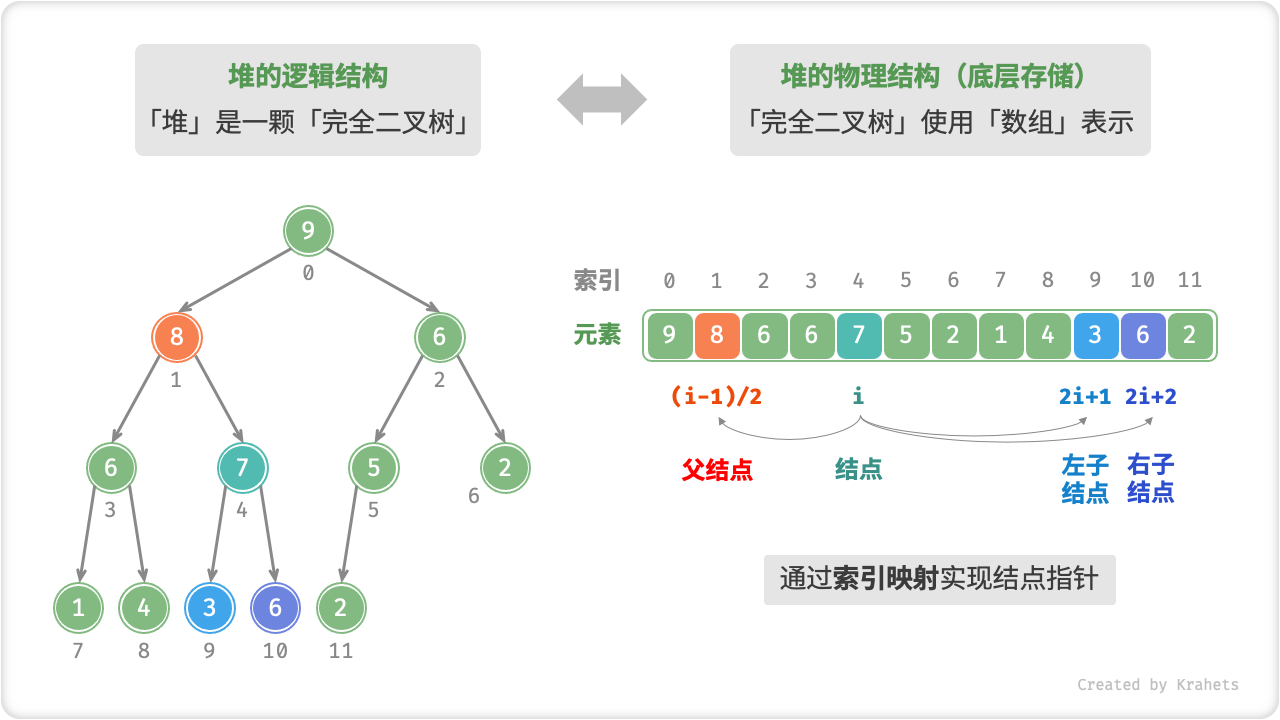
我们将索引映射公式封装成函数,以便后续使用。
=== "Java"
```java title="my_heap.java"
// 使用列表而非数组,这样无需考虑扩容问题
List<Integer> maxHeap;
/* 构造函数,建立空堆 */
public MaxHeap() {
maxHeap = new ArrayList<>();
}
/* 获取左子结点索引 */
int left(int i) {
return 2 * i + 1;
}
/* 获取右子结点索引 */
int right(int i) {
return 2 * i + 2;
}
/* 获取父结点索引 */
int parent(int i) {
return (i - 1) / 2; // 向下整除
}
```
=== "C++"
```cpp title="my_heap.cpp"
```
=== "Python"
```python title="my_heap.py"
```
=== "Go"
```go title="my_heap.go"
type maxHeap struct {
// 使用切片而非数组,这样无需考虑扩容问题
data []any
}
/* 构造函数,建立空堆 */
func newHeap() *maxHeap {
return &maxHeap{
data: make([]any, 0),
}
}
/* 获取左子结点索引 */
func (h *maxHeap) left(i int) int {
return 2*i + 1
}
/* 获取右子结点索引 */
func (h *maxHeap) right(i int) int {
return 2*i + 2
}
/* 获取父结点索引 */
func (h *maxHeap) parent(i int) int {
// 向下整除
return (i - 1) / 2
}
```
=== "JavaScript"
```js title="my_heap.js"
```
=== "TypeScript"
```typescript title="my_heap.ts"
```
=== "C"
```c title="my_heap.c"
```
=== "C#"
```csharp title="my_heap.cs"
```
=== "Swift"
```swift title="my_heap.swift"
var maxHeap: [Int]
/* 构造函数,建立空堆 */
init() {
maxHeap = []
}
/* 获取左子结点索引 */
func left(i: Int) -> Int {
2 * i + 1
}
/* 获取右子结点索引 */
func right(i: Int) -> Int {
2 * i + 2
}
/* 获取父结点索引 */
func parent(i: Int) -> Int {
(i - 1) / 2 // 向下整除
}
```
访问堆顶元素
堆顶元素是二叉树的根结点,即列表首元素。
=== "Java"
```java title="my_heap.java"
/* 访问堆顶元素 */
public int peek() {
return maxHeap.get(0);
}
```
=== "C++"
```cpp title="my_heap.cpp"
```
=== "Python"
```python title="my_heap.py"
```
=== "Go"
```go title="my_heap.go"
/* 访问堆顶元素 */
func (h *maxHeap) peek() any {
return h.data[0]
}
```
=== "JavaScript"
```js title="my_heap.js"
```
=== "TypeScript"
```typescript title="my_heap.ts"
```
=== "C"
```c title="my_heap.c"
```
=== "C#"
```csharp title="my_heap.cs"
```
=== "Swift"
```swift title="my_heap.swift"
/* 访问堆顶元素 */
func peek() -> Int {
maxHeap[0]
}
```
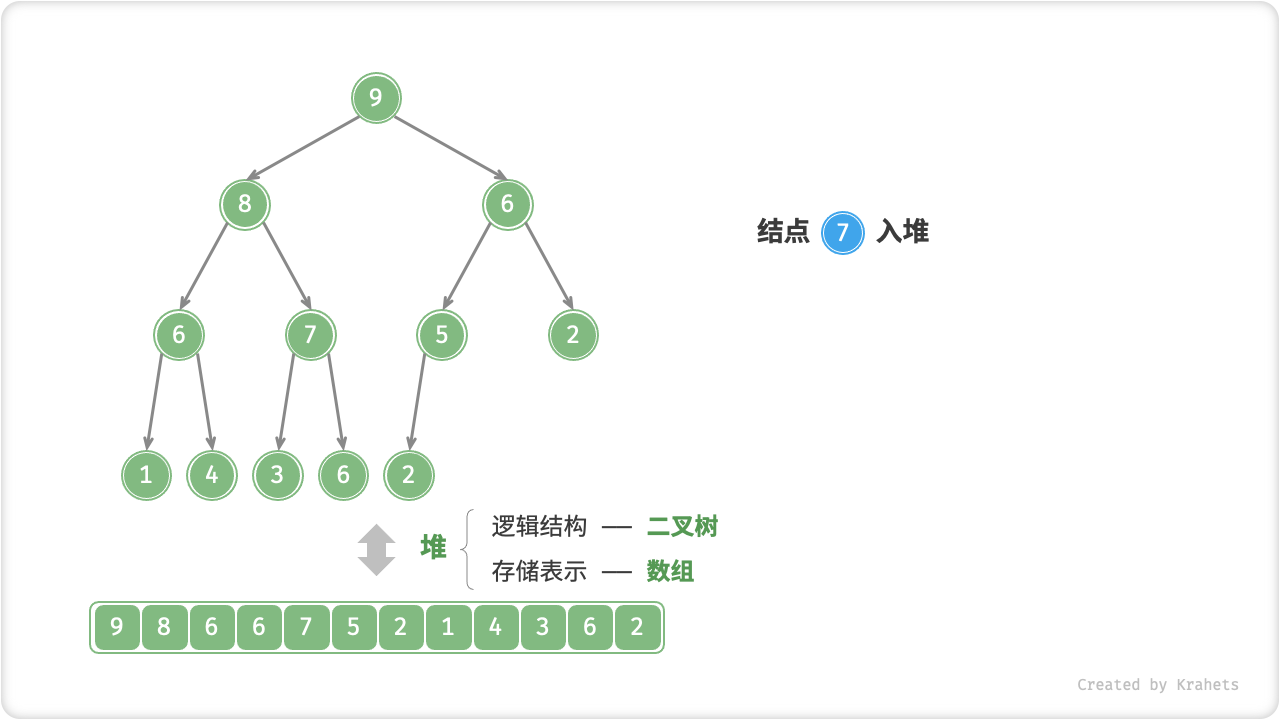
元素入堆
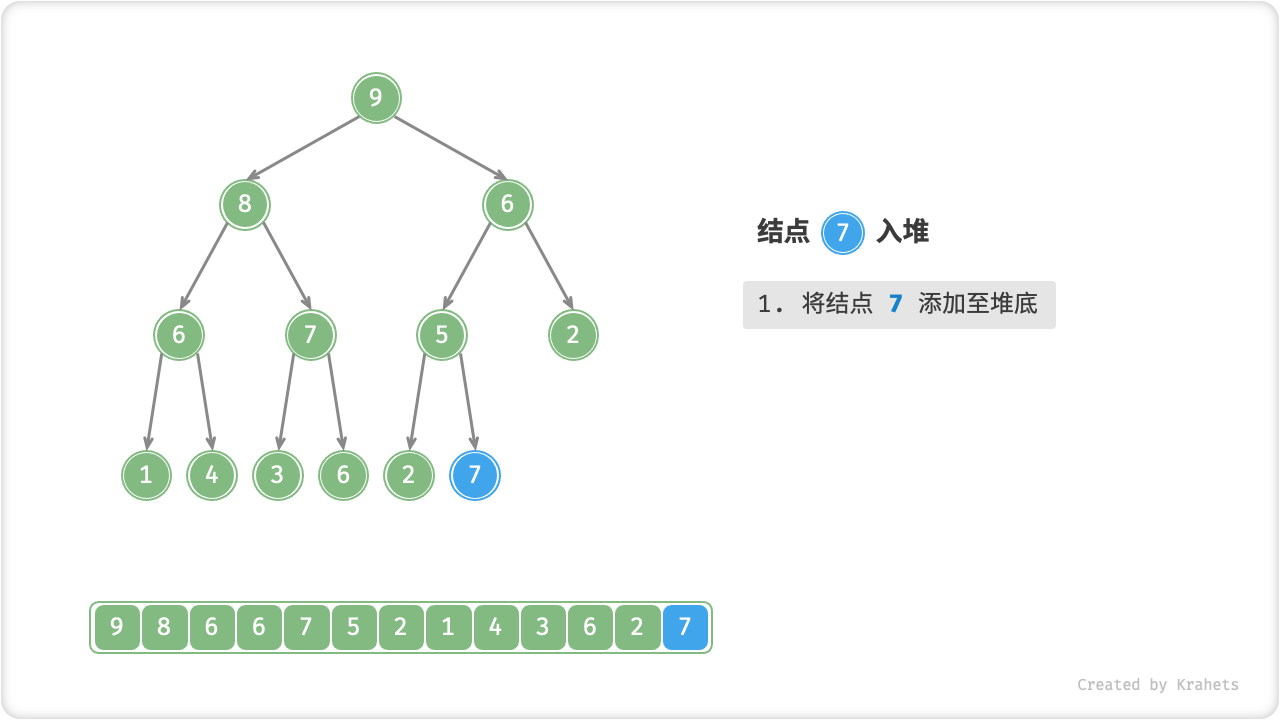
给定元素 val ,我们先将其添加到堆底。添加后,由于 val 可能大于堆中其它元素,此时堆的成立条件可能已经被破坏,因此需要修复从插入结点到根结点这条路径上的各个结点,该操作被称为「堆化 Heapify」。
考虑从入堆结点开始,从底至顶执行堆化。具体地,比较插入结点与其父结点的值,若插入结点更大则将它们交换;并循环以上操作,从底至顶地修复堆中的各个结点;直至越过根结点时结束,或当遇到无需交换的结点时提前结束。
=== "Step 1"
=== "Step 2"
=== "Step 3"
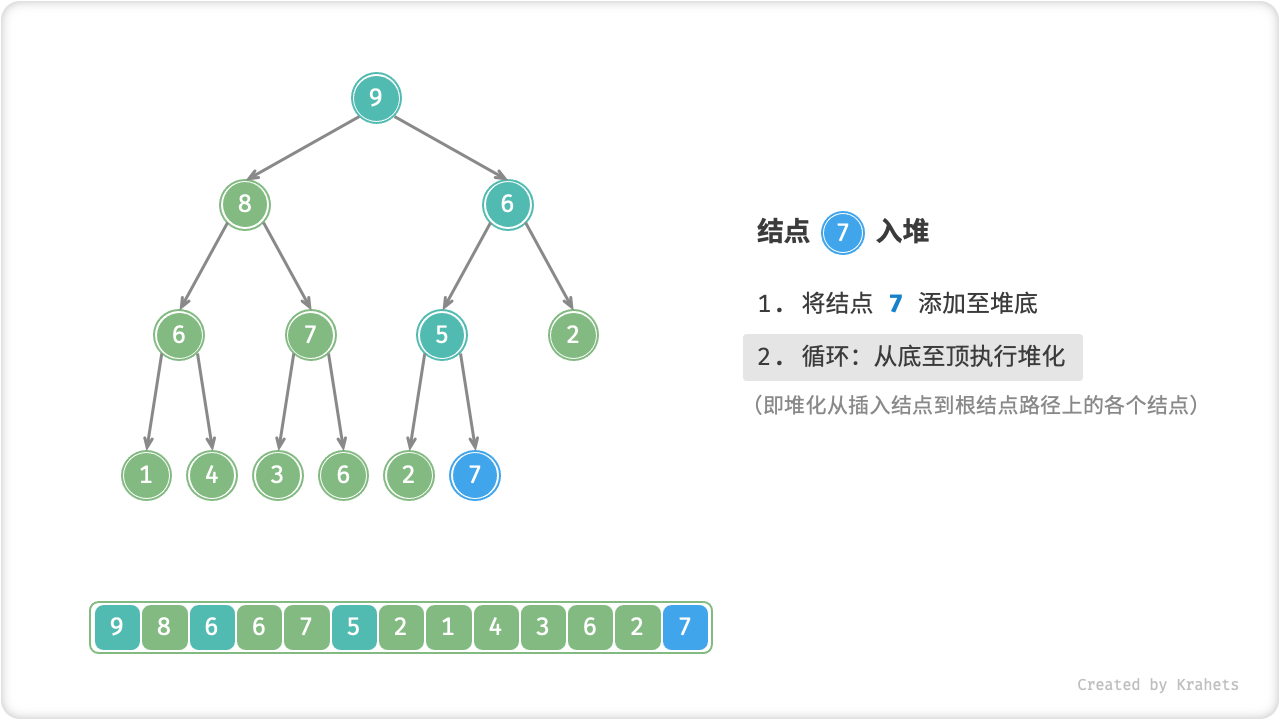
=== "Step 4"
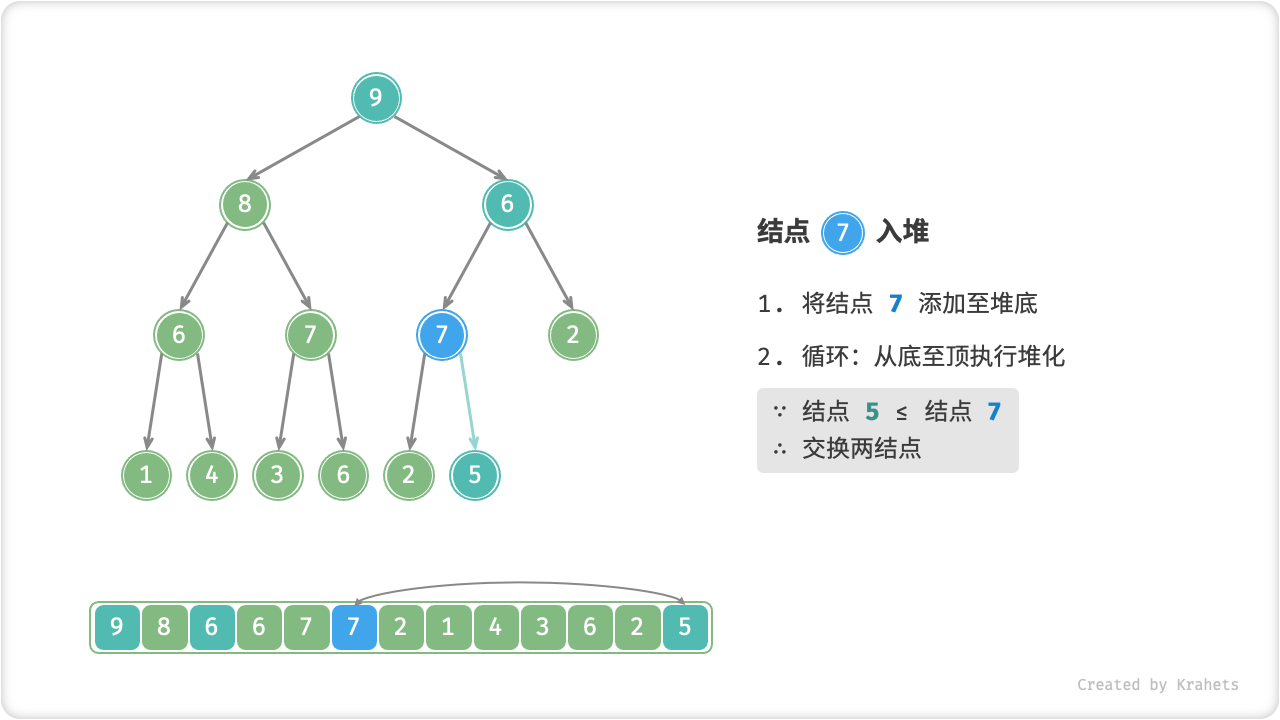
=== "Step 5"
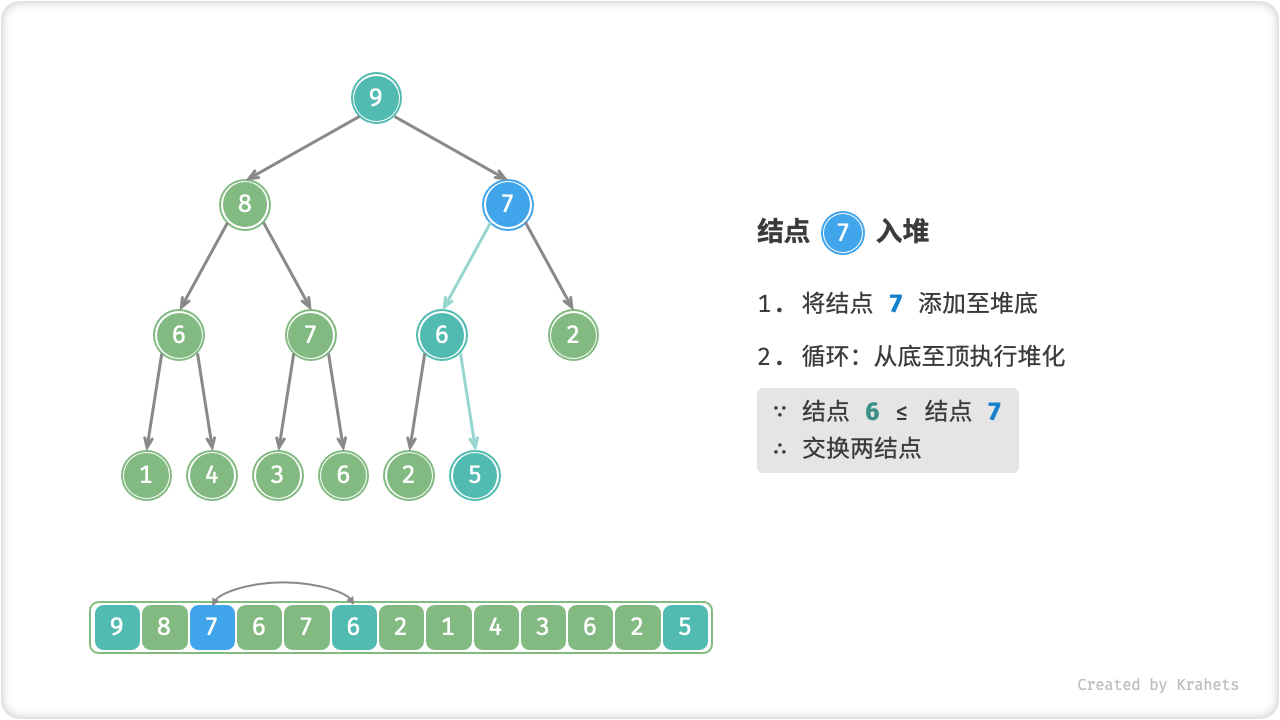
=== "Step 6"
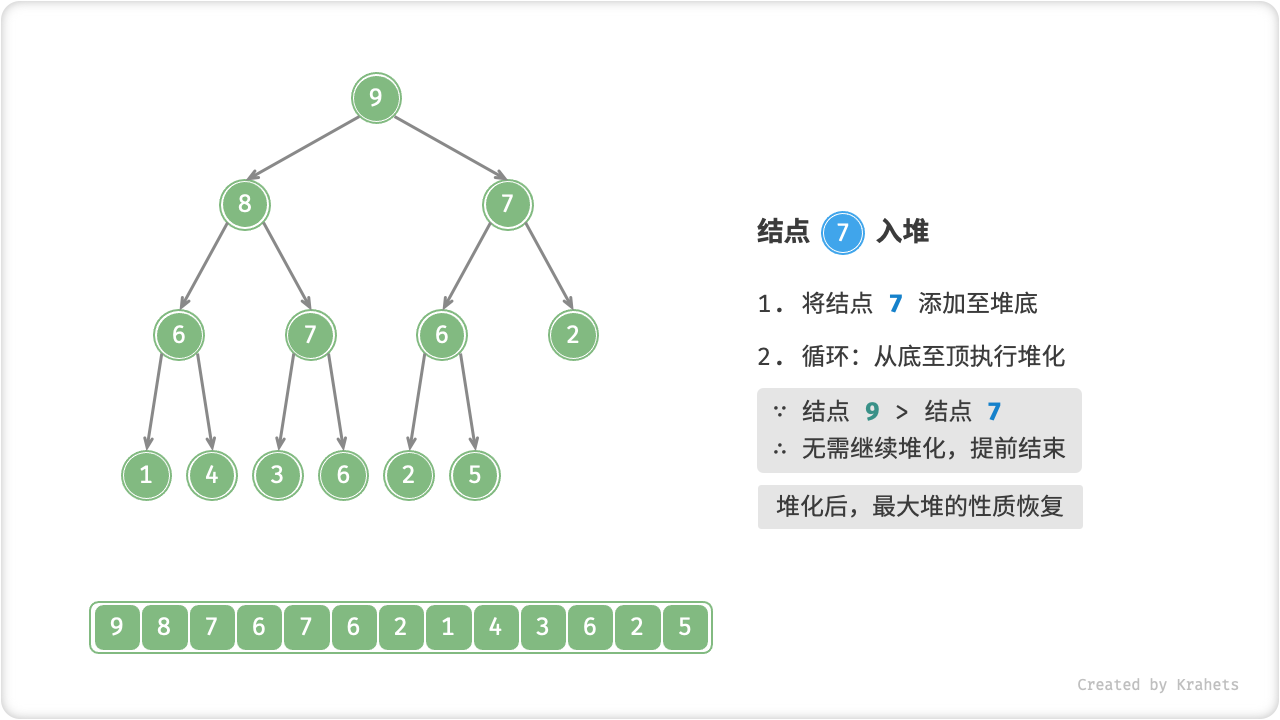
设结点总数为 n ,则树的高度为 O(\log n) ,易得堆化操作的循环轮数最多为 O(\log n) ,因而元素入堆操作的时间复杂度为 O(\log n) 。
=== "Java"
```java title="my_heap.java"
/* 元素入堆 */
void push(int val) {
// 添加结点
maxHeap.add(val);
// 从底至顶堆化
siftUp(size() - 1);
}
/* 从结点 i 开始,从底至顶堆化 */
void siftUp(int i) {
while (true) {
// 获取结点 i 的父结点
int p = parent(i);
// 若“越过根结点”或“结点无需修复”,则结束堆化
if (p < 0 || maxHeap.get(i) <= maxHeap.get(p))
break;
// 交换两结点
swap(i, p);
// 循环向上堆化
i = p;
}
}
```
=== "C++"
```cpp title="my_heap.cpp"
```
=== "Python"
```python title="my_heap.py"
```
=== "Go"
```go title="my_heap.go"
/* 元素入堆 */
func (h *maxHeap) push(val any) {
// 添加结点
h.data = append(h.data, val)
// 从底至顶堆化
h.siftUp(len(h.data) - 1)
}
/* 从结点 i 开始,从底至顶堆化 */
func (h *maxHeap) siftUp(i int) {
for true {
// 获取结点 i 的父结点
p := h.parent(i)
// 当“越过根结点”或“结点无需修复”时,结束堆化
if p < 0 || h.data[i].(int) <= h.data[p].(int) {
break
}
// 交换两结点
h.swap(i, p)
// 循环向上堆化
i = p
}
}
```
=== "JavaScript"
```js title="my_heap.js"
```
=== "TypeScript"
```typescript title="my_heap.ts"
```
=== "C"
```c title="my_heap.c"
```
=== "C#"
```csharp title="my_heap.cs"
```
=== "Swift"
```swift title="my_heap.swift"
/* 元素入堆 */
func push(val: Int) {
// 添加结点
maxHeap.append(val)
// 从底至顶堆化
siftUp(i: size() - 1)
}
/* 从结点 i 开始,从底至顶堆化 */
func siftUp(i: Int) {
var i = i
while true {
// 获取结点 i 的父结点
let p = parent(i: i)
// 当“越过根结点”或“结点无需修复”时,结束堆化
if p < 0 || maxHeap[i] <= maxHeap[p] {
break
}
// 交换两结点
swap(i: i, j: p)
// 循环向上堆化
i = p
}
}
```
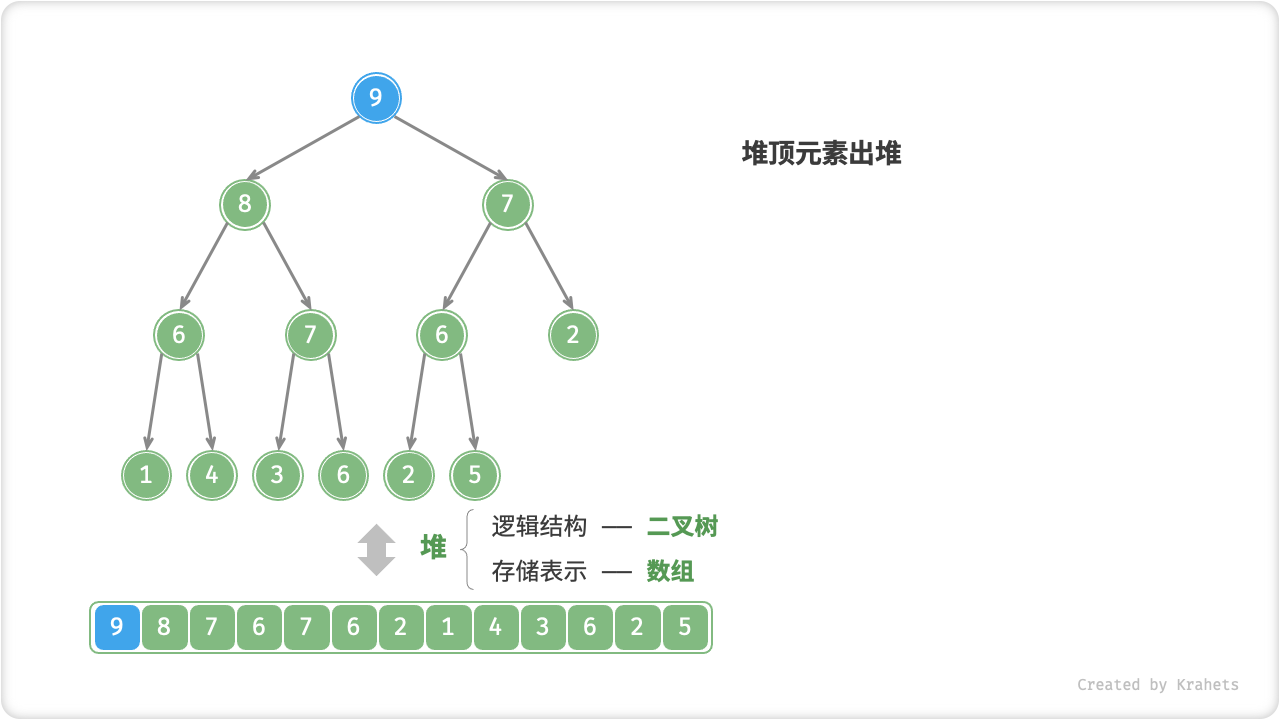
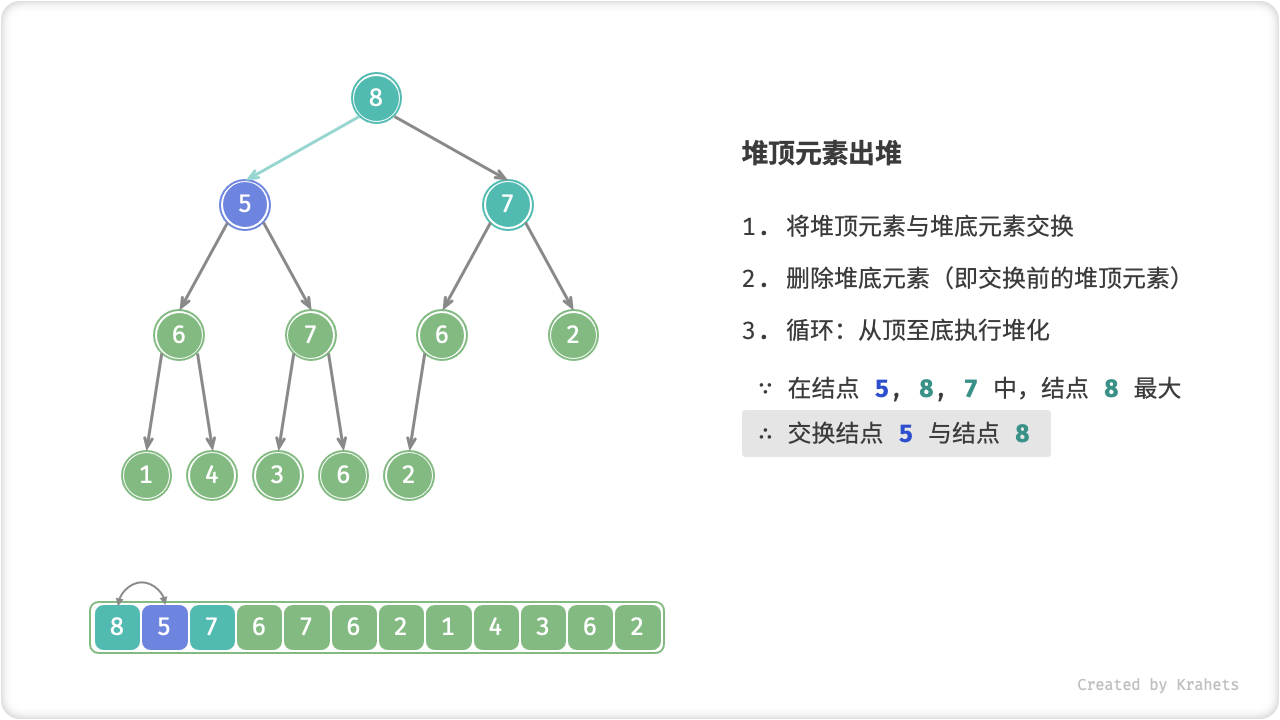
堆顶元素出堆
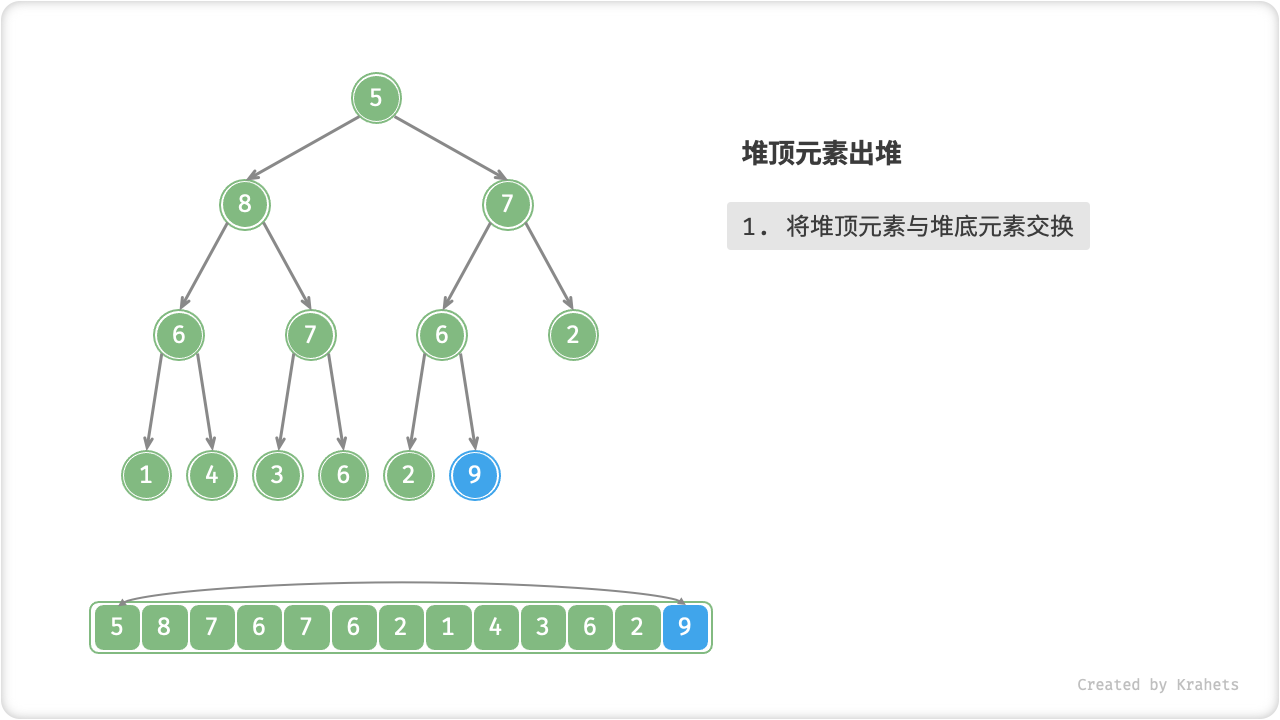
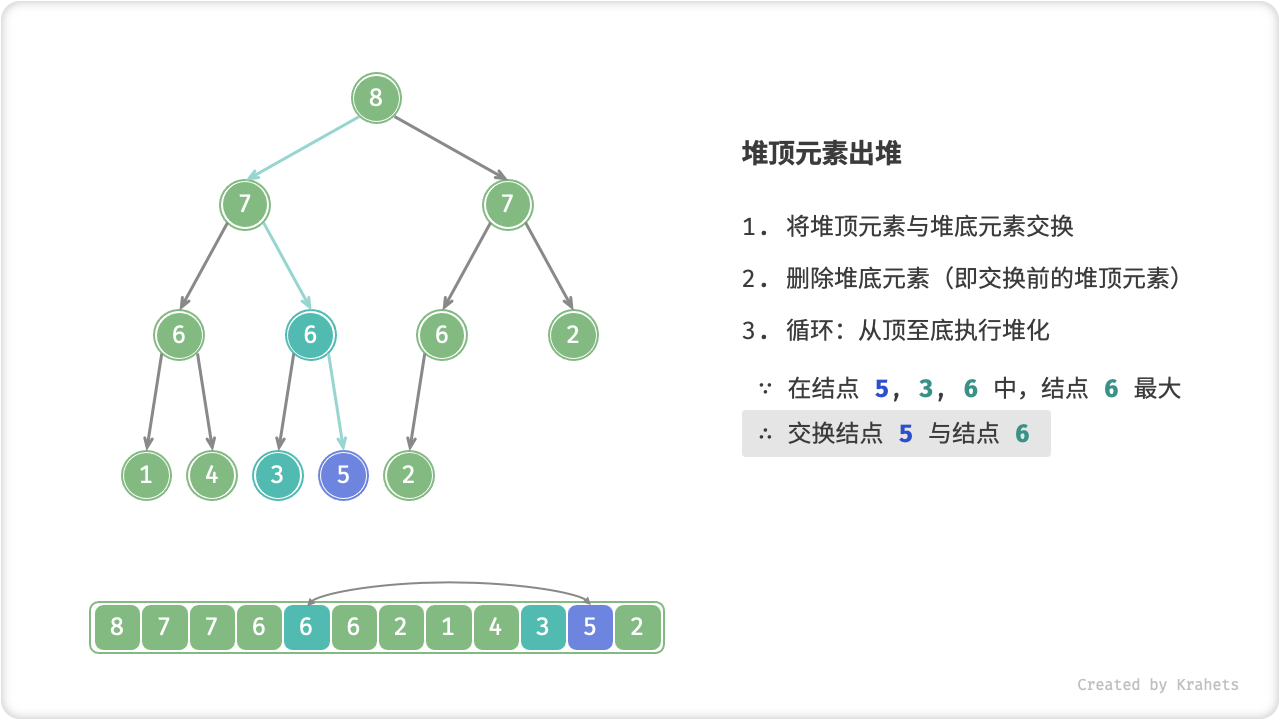
堆顶元素是二叉树根结点,即列表首元素,如果我们直接将首元素从列表中删除,则二叉树中所有结点都会随之发生移位(索引发生变化),这样后续使用堆化修复就很麻烦了。为了尽量减少元素索引变动,采取以下操作步骤:
- 交换堆顶元素与堆底元素(即交换根结点与最右叶结点);
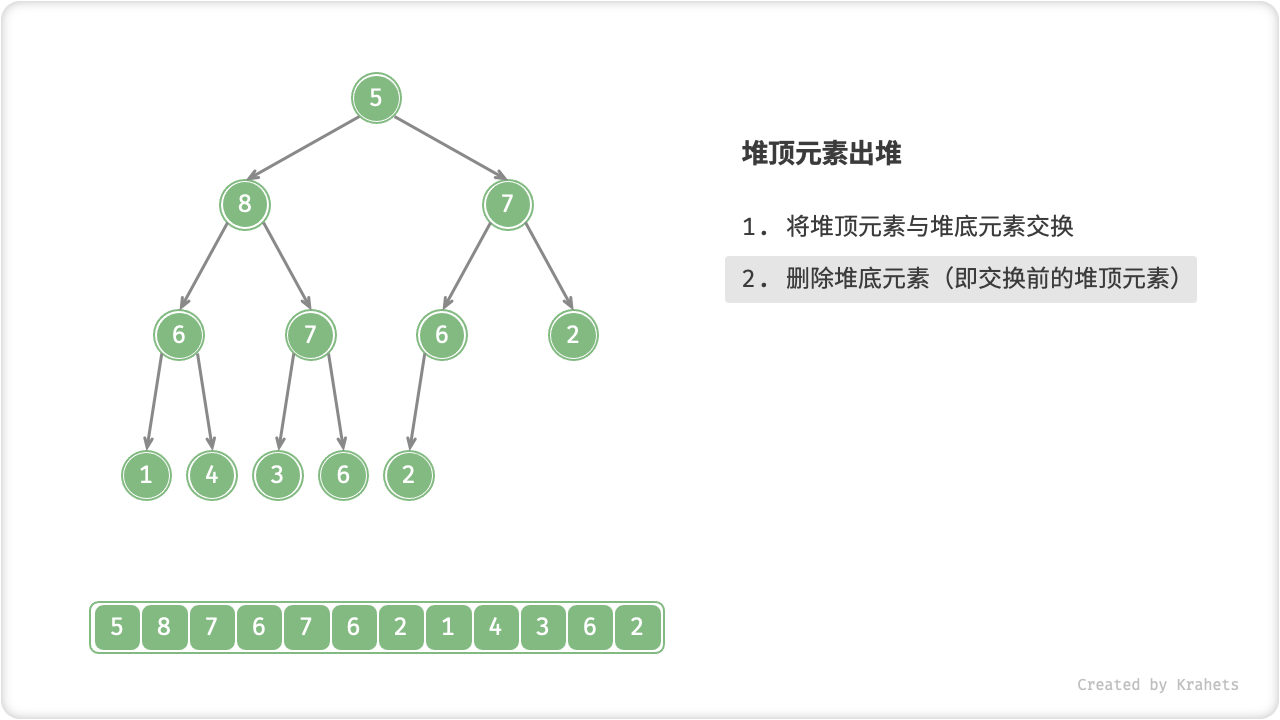
- 交换完成后,将堆底从列表中删除(注意,因为已经交换,实际上删除的是原来的堆顶元素);
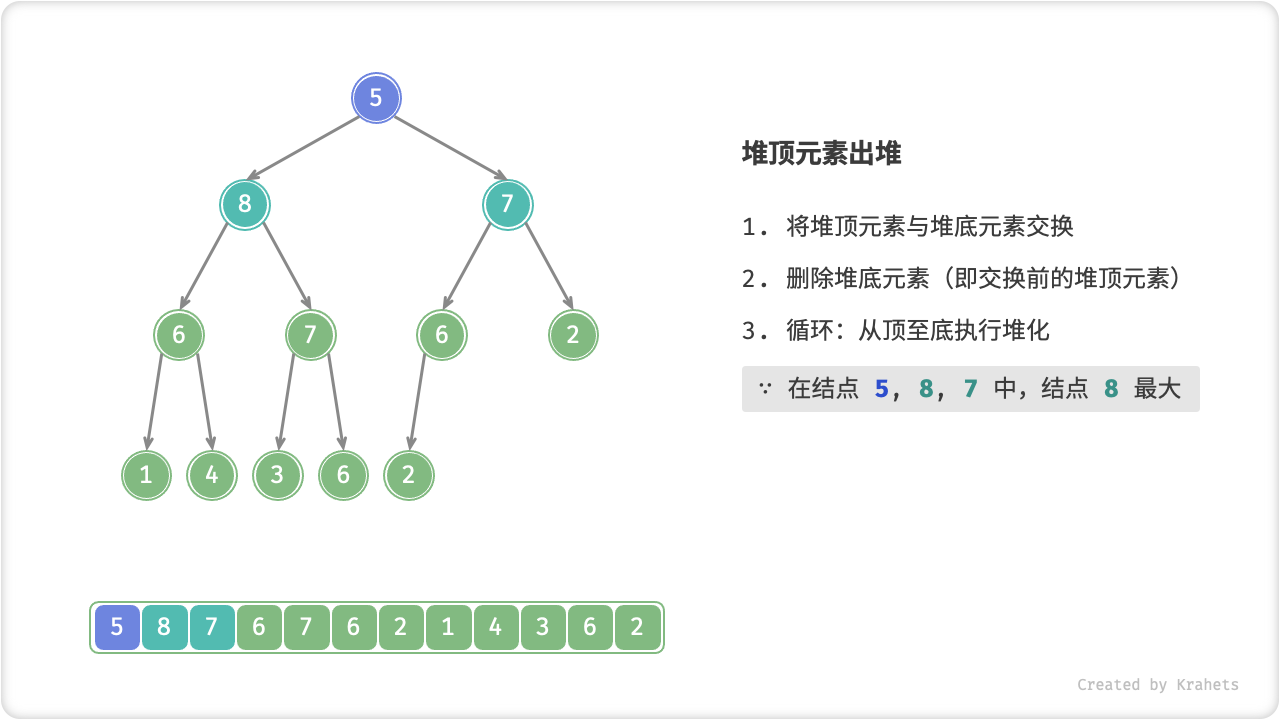
- 从根结点开始,从顶至底执行堆化;
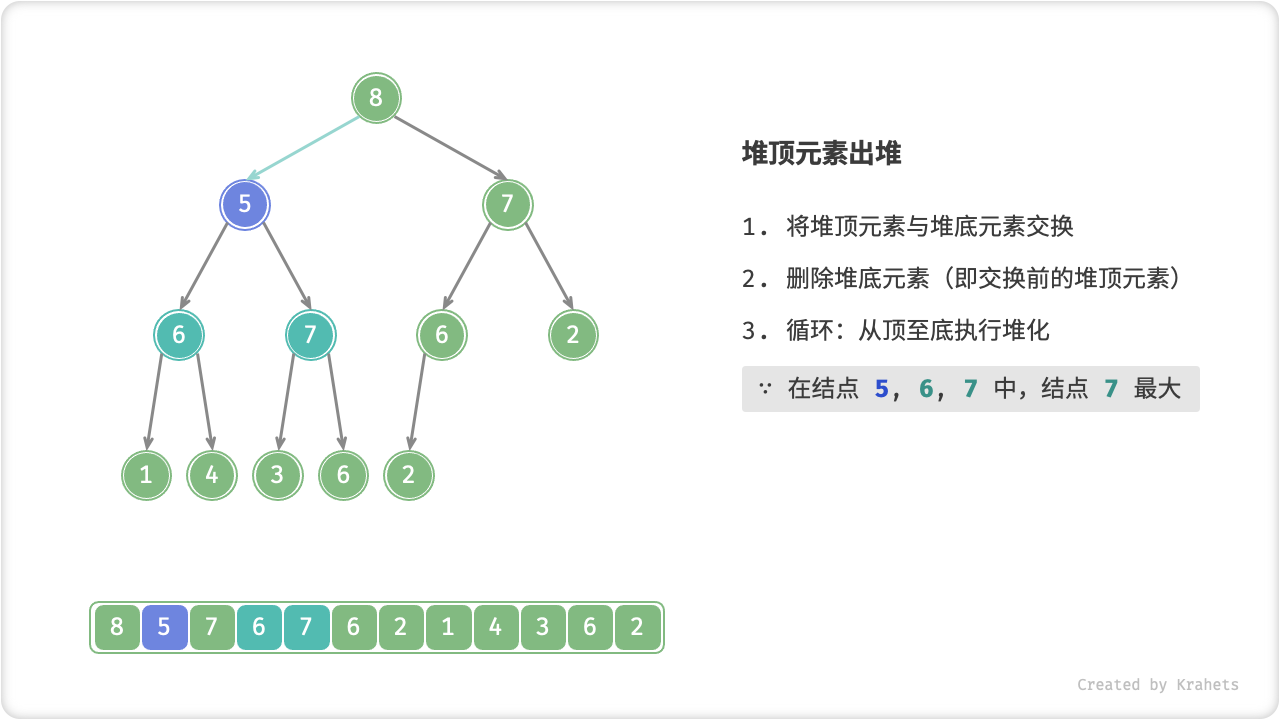
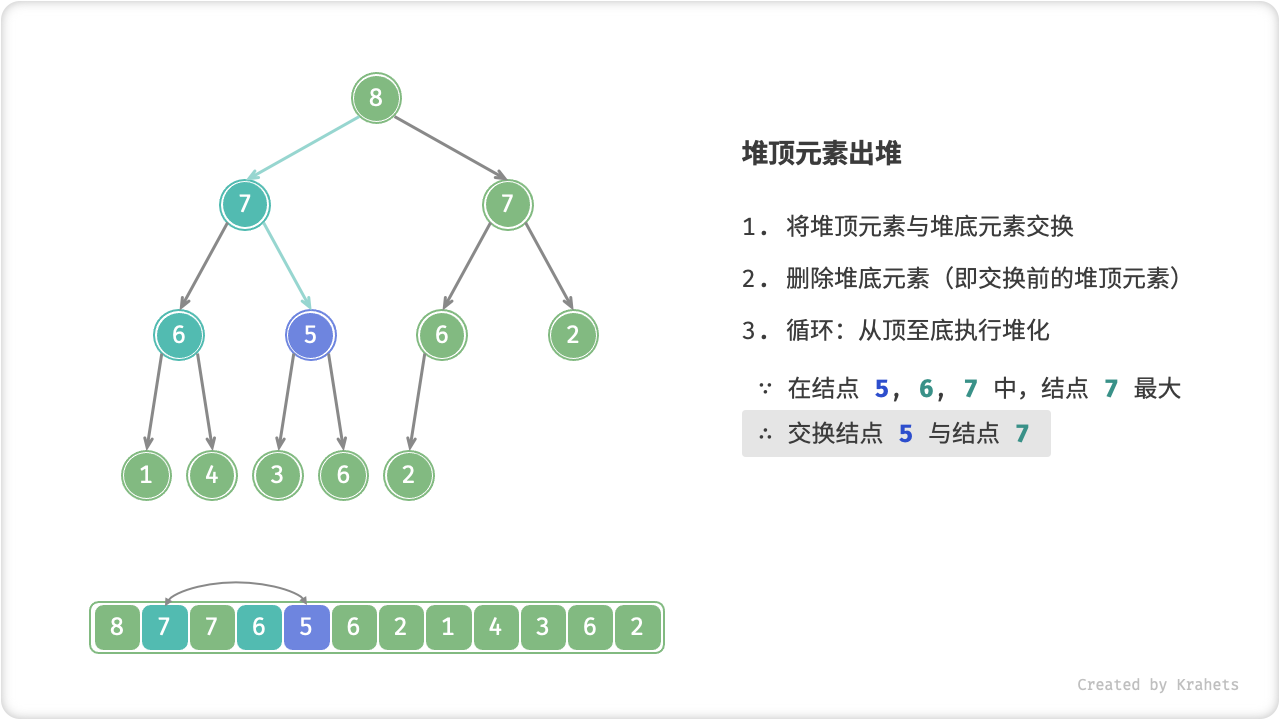
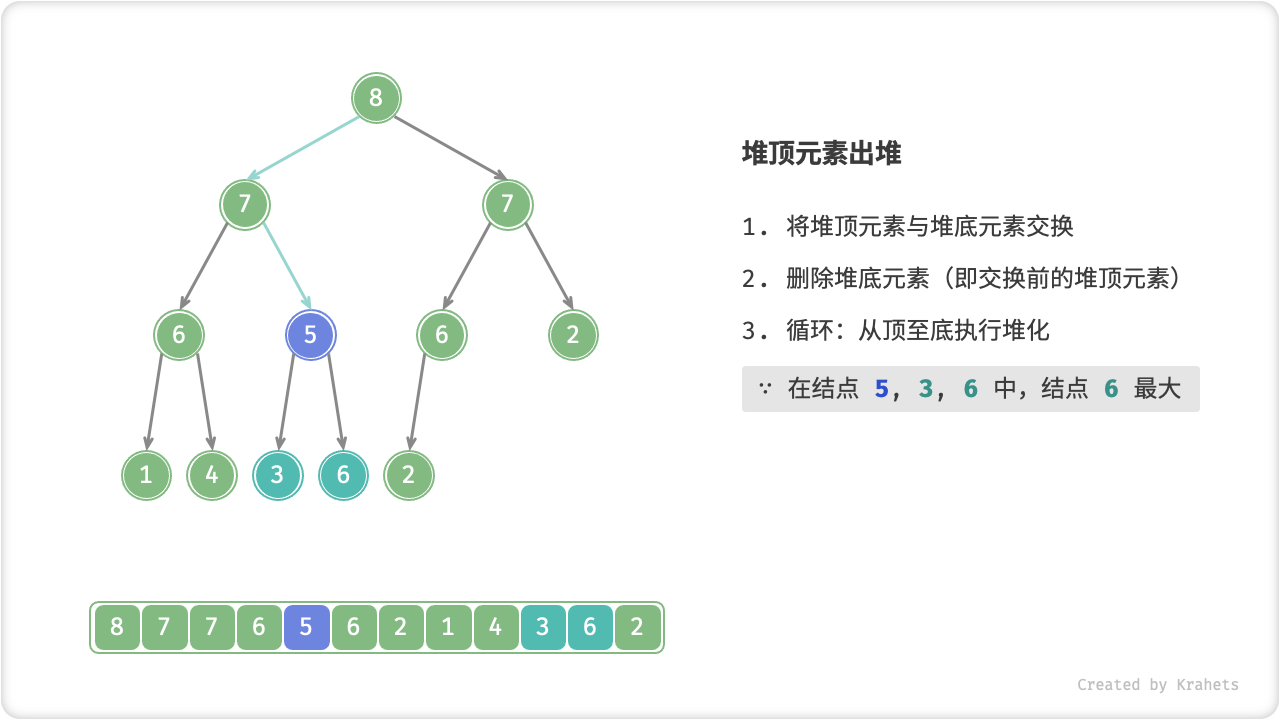
顾名思义,从顶至底堆化的操作方向与从底至顶堆化相反,我们比较根结点的值与其两个子结点的值,将最大的子结点与根结点执行交换,并循环以上操作,直到越过叶结点时结束,或当遇到无需交换的结点时提前结束。
=== "Step 1"
=== "Step 2"
=== "Step 3"
=== "Step 4"
=== "Step 5"
=== "Step 6"
=== "Step 7"
=== "Step 8"
=== "Step 9"
=== "Step 10"
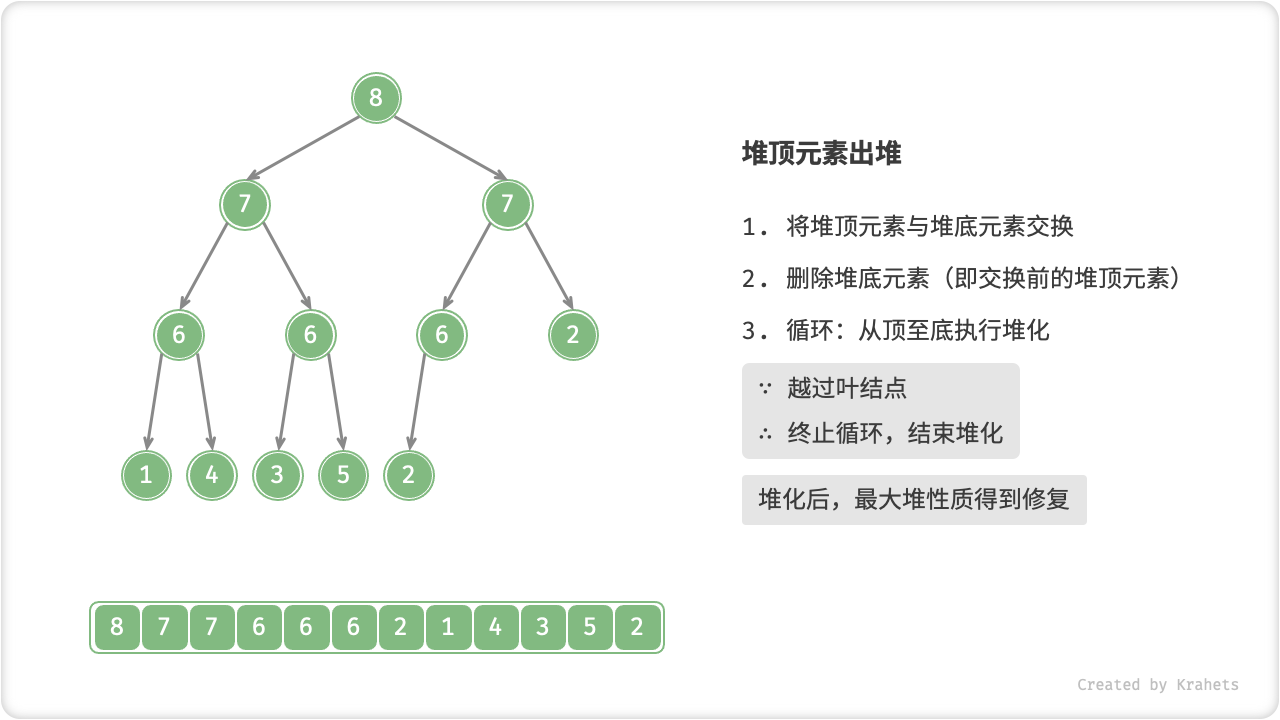
与元素入堆操作类似,堆顶元素出堆操作的时间复杂度为 O(\log n) 。
=== "Java"
```java title="my_heap.java"
/* 元素出堆 */
int poll() {
// 判空处理
if (isEmpty())
throw new EmptyStackException();
// 交换根结点与最右叶结点(即交换首元素与尾元素)
swap(0, size() - 1);
// 删除结点
int val = maxHeap.remove(size() - 1);
// 从顶至底堆化
siftDown(0);
// 返回堆顶元素
return val;
}
/* 从结点 i 开始,从顶至底堆化 */
void siftDown(int i) {
while (true) {
// 判断结点 i, l, r 中值最大的结点,记为 ma
int l = left(i), r = right(i), ma = i;
if (l < size() && maxHeap.get(l) > maxHeap.get(ma))
ma = l;
if (r < size() && maxHeap.get(r) > maxHeap.get(ma))
ma = r;
// 若“结点 i 最大”或“越过叶结点”,则结束堆化
if (ma == i) break;
// 交换两结点
swap(i, ma);
// 循环向下堆化
i = ma;
}
}
```
=== "C++"
```cpp title="my_heap.cpp"
```
=== "Python"
```python title="my_heap.py"
```
=== "Go"
```go title="my_heap.go"
/* 元素出堆 */
func (h *maxHeap) poll() any {
// 判空处理
if h.isEmpty() {
fmt.Println("error")
return nil
}
// 交换根结点与最右叶结点(即交换首元素与尾元素)
h.swap(0, h.size()-1)
// 删除结点
val := h.data[len(h.data)-1]
h.data = h.data[:len(h.data)-1]
// 从顶至底堆化
h.siftDown(0)
// 返回堆顶元素
return val
}
/* 从结点 i 开始,从顶至底堆化 */
func (h *maxHeap) siftDown(i int) {
for true {
// 判断结点 i, l, r 中值最大的结点,记为 max
l, r, max := h.left(i), h.right(i), i
if l < h.size() && h.data[l].(int) > h.data[max].(int) {
max = l
}
if r < h.size() && h.data[r].(int) > h.data[max].(int) {
max = r
}
// 若结点 i 最大或索引 l, r 越界,则无需继续堆化,跳出
if max == i {
break
}
// 交换两结点
h.swap(i, max)
// 循环向下堆化
i = max
}
}
```
=== "JavaScript"
```js title="my_heap.js"
```
=== "TypeScript"
```typescript title="my_heap.ts"
```
=== "C"
```c title="my_heap.c"
```
=== "C#"
```csharp title="my_heap.cs"
```
=== "Swift"
```swift title="my_heap.swift"
/* 元素出堆 */
func poll() -> Int {
// 判空处理
if isEmpty() {
fatalError("堆为空")
}
// 交换根结点与最右叶结点(即交换首元素与尾元素)
swap(i: 0, j: size() - 1)
// 删除结点
let val = maxHeap.remove(at: size() - 1)
// 从顶至底堆化
siftDown(i: 0)
// 返回堆顶元素
return val
}
/* 从结点 i 开始,从顶至底堆化 */
func siftDown(i: Int) {
var i = i
while true {
// 判断结点 i, l, r 中值最大的结点,记为 ma
let l = left(i: i)
let r = right(i: i)
var ma = i
if l < size(), maxHeap[l] > maxHeap[ma] {
ma = l
}
if r < size(), maxHeap[r] > maxHeap[ma] {
ma = r
}
// 若结点 i 最大或索引 l, r 越界,则无需继续堆化,跳出
if ma == i {
break
}
// 交换两结点
swap(i: i, j: ma)
// 循环向下堆化
i = ma
}
}
```
输入数据并建堆 *
如果我们想要直接输入一个列表并将其建堆,那么该怎么做呢?最直接地,考虑使用「元素入堆」方法,将列表元素依次入堆。元素入堆的时间复杂度为 O(n) ,而平均长度为 \frac{n}{2} ,因此该方法的总体时间复杂度为 O(n \log n) 。
然而,存在一种更加优雅的建堆方法。设结点数量为 n ,我们先将列表所有元素原封不动添加进堆,然后迭代地对各个结点执行「从顶至底堆化」。当然,无需对叶结点执行堆化,因为其没有子结点。
=== "Java"
```java title="my_heap.java"
/* 构造函数,根据输入列表建堆 */
public MaxHeap(List<Integer> nums) {
// 将列表元素原封不动添加进堆
maxHeap = new ArrayList<>(nums);
// 堆化除叶结点以外的其他所有结点
for (int i = parent(size() - 1); i >= 0; i--) {
siftDown(i);
}
}
```
=== "C++"
```cpp title="my_heap.cpp"
```
=== "Python"
```python title="my_heap.py"
```
=== "Go"
```go title="my_heap.go"
/* 构造函数,根据切片建堆 */
func newMaxHeap(nums []any) *maxHeap {
// 将列表元素原封不动添加进堆
h := &maxHeap{data: nums}
// 堆化除叶结点以外的其他所有结点
for i := len(h.data) - 1; i >= 0; i-- {
h.siftDown(i)
}
return h
}
```
=== "JavaScript"
```js title="my_heap.js"
```
=== "TypeScript"
```typescript title="my_heap.ts"
```
=== "C"
```c title="my_heap.c"
```
=== "C#"
```csharp title="my_heap.cs"
```
=== "Swift"
```swift title="my_heap.swift"
/* 构造函数,根据输入列表建堆 */
init(nums: [Int]) {
// 将列表元素原封不动添加进堆
maxHeap = nums
// 堆化除叶结点以外的其他所有结点
for i in stride(from: parent(i: size() - 1), through: 0, by: -1) {
siftDown(i: i)
}
}
```
那么,第二种建堆方法的时间复杂度时多少呢?我们来做一下简单推算。
- 完全二叉树中,设结点总数为
n,则叶结点数量为(n + 1) / 2,其中/为向下整除。因此在排除叶结点后,需要堆化结点数量为(n - 1)/2,即为O(n); - 从顶至底堆化中,每个结点最多堆化至叶结点,因此最大迭代次数为二叉树高度
O(\log n);
将上述两者相乘,可得时间复杂度为 O(n \log n) 。然而,该估算结果仍不够准确,因为我们没有考虑到 二叉树底层结点远多于顶层结点 的性质。
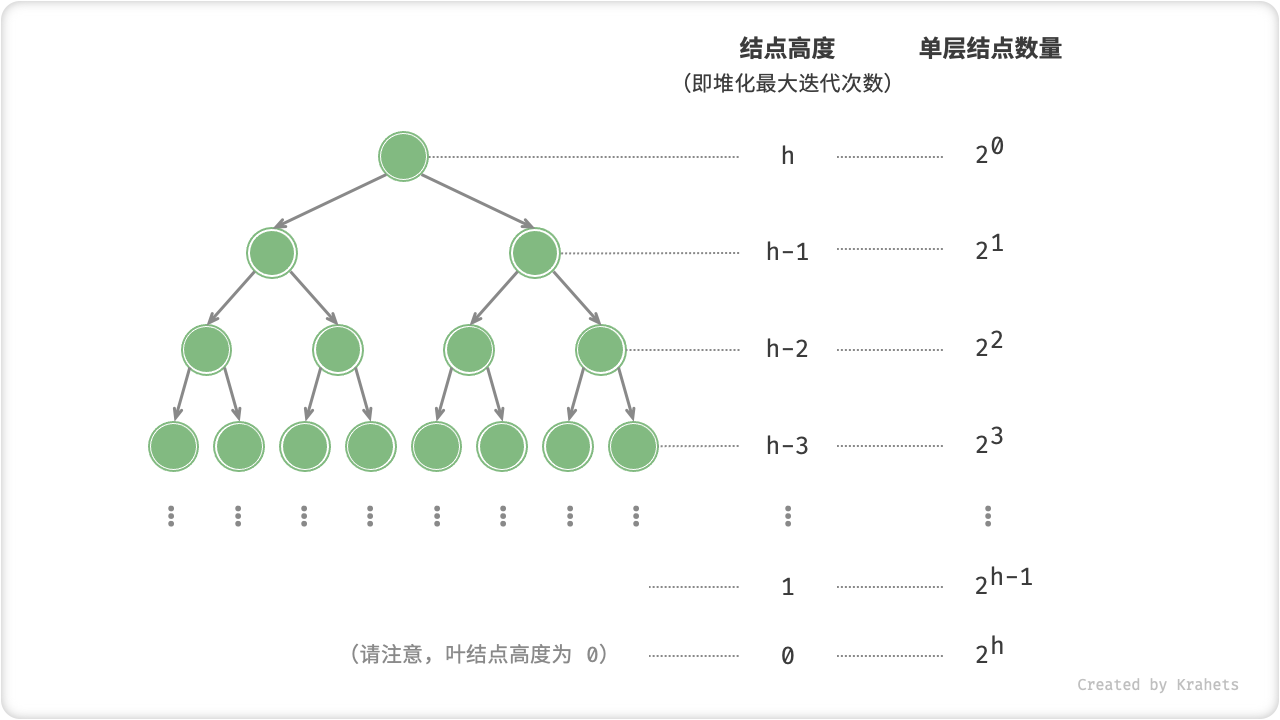
下面我们来尝试展开计算。为了减小计算难度,我们假设树是一个「完美二叉树」,该假设不会影响计算结果的正确性。设二叉树(即堆)结点数量为 n ,树高度为 h 。上文提到,结点堆化最大迭代次数等于该结点到叶结点的距离,而这正是“结点高度”。因此,我们将各层的“结点数量 \times 结点高度”求和,即可得到所有结点的堆化的迭代次数总和。
T(h) = 2^0h + 2^1(h-1) + 2^2(h-2) + \cdots + 2^{(h-1)}\times1
化简上式需要借助中学的数列知识,先对 T(h) 乘以 2 ,易得
\begin{aligned}
T(h) & = 2^0h + 2^1(h-1) + 2^2(h-2) + \cdots + 2^{h-1}\times1 \newline
2 T(h) & = 2^1h + 2^2(h-1) + 2^3(h-2) + \cdots + 2^{h}\times1 \newline
\end{aligned}
使用错位相减法,令下式 2 T(h) 减去上式 T(h) ,可得
2T(h) - T(h) = T(h) = -2^0h + 2^1 + 2^2 + \cdots + 2^{h-1} + 2^h
观察上式,T(h) 是一个等比数列,可直接使用求和公式,得到时间复杂度为
\begin{aligned}
T(h) & = 2 \frac{1 - 2^h}{1 - 2} - h \newline
& = 2^{h+1} - h \newline
& = O(2^h)
\end{aligned}
进一步地,高度为 h 的完美二叉树的结点数量为 n = 2^{h+1} - 1 ,易得复杂度为 O(2^h) = O(n)。以上推算表明,输入列表并建堆的时间复杂度为 O(n) ,非常高效。
堆常见应用
- 优先队列。堆常作为实现优先队列的首选数据结构,入队和出队操作时间复杂度为
O(\log n),建队操作为O(n),皆非常高效。 - 堆排序。给定一组数据,我们使用其建堆,并依次全部弹出,则可以得到有序的序列。当然,堆排序一般无需弹出元素,仅需每轮将堆顶元素交换至数组尾部并减小堆的长度即可。
- 获取最大的
k个元素。这既是一道经典算法题目,也是一种常见应用,例如选取热度前 10 的新闻作为微博热搜,选取前 10 销量的商品等。